Browser Automation Benchmark: LLM Performance Comparison on 100 Hard Web Tasks
By
MagMueller
Front-window bakery material. Catches the eye, delivers the goods.
Summary
The article presents a new open-source benchmark called BU Bench V1 for evaluating LLM models on browser automation tasks. It includes 100 hand-selected challenging tasks drawn from five established sources, with Browser Use Cloud scoring 78% and outperforming the best open-source model by 16 points. The benchmark aims to provide standardized evaluation for comparing different models and versions in web automation performance.
Key quotes
· 5 pulledTo truly understand our agent performance, we built a suite of internal tools for evaluating our agent in a standardized and repeatable way so we can compare versions and models and continuously improve.
This is our first open source benchmark. BU Bench V1: 100 hand-selected tasks that are hard but possible, drawn from five established sources.
Browser Use Cloud scores 78%, 16 points ahead of the best open-source model.
We take evaluations seriously. As of now, we have over 600,000 tasks run in testing.
SourceTasksDescriptionCustom20Page interaction challenges (iframes, drag-and-drop, complex forms)
You might also wanna read

Web Bench: A Comprehensive Benchmark for AI Browser Agent Performance
Web Bench is a new benchmark platform designed to evaluate and compare AI browser agents' performance in web navigation tasks. It provides c
 Product Hunt·1y ago
Product Hunt·1y ago
LLM Stats: Platform for Comparing AI Language Models by Benchmarks, Cost, and Capabilities
LLM Stats is a platform that allows users to compare various AI language models (LLMs) across multiple dimensions including performance benc
Product Hunt·7mo ago
LiveBrowseComp reveals LLM search agents rely on memorized knowledge, not genuine web searching
This paper introduces the concept of Intrinsic Knowledge Dependence (IKD), showing that LLM-based search agents often rely on pre-trained kn
Shopping Companion: Benchmarking and Training LLM Agents for Long-Horizon Preference-Grounded E-Commerce Tasks
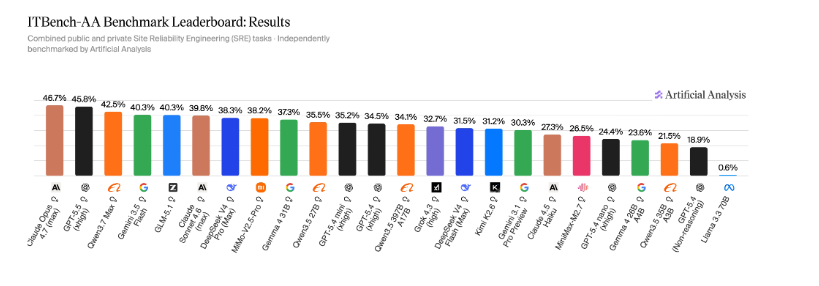
New ITBench-AA Benchmark Reveals AI Models Struggle with Enterprise SRE Tasks
ITBench-AA, a new benchmark developed by Artificial Analysis and IBM Research over six months, reveals that leading AI models like Claude Op

MobilityBench: A New Benchmark for Evaluating LLM-Based Route-Planning Agents Using Real-World Mobility Data
This paper introduces MobilityBench, a scalable benchmark for evaluating LLM-based route-planning agents in real-world mobility scenarios. B