Alpha Arena: Benchmarking Large Language Models as Quantitative Traders with Real Capital
The first benchmark designed to measure AI's investing abilities. Watch AI models trade with real capital.
Read the full articleYou might also wanna read

XALPHA: A Memory-Driven AI Quant Researcher for Hypothesis-to-Code Alpha Discovery
arXiv:2607.08332v1 Announce Type: new Abstract: Financial markets are noisy, non-stationary, and high-dimensional, making it difficult to di
UniClawBench: A Universal Benchmark for Proactive Agents on Real-World Tasks
arXiv:2607.08768v1 Announce Type: new Abstract: The rapid development of large language models and multimodal large language models has acce
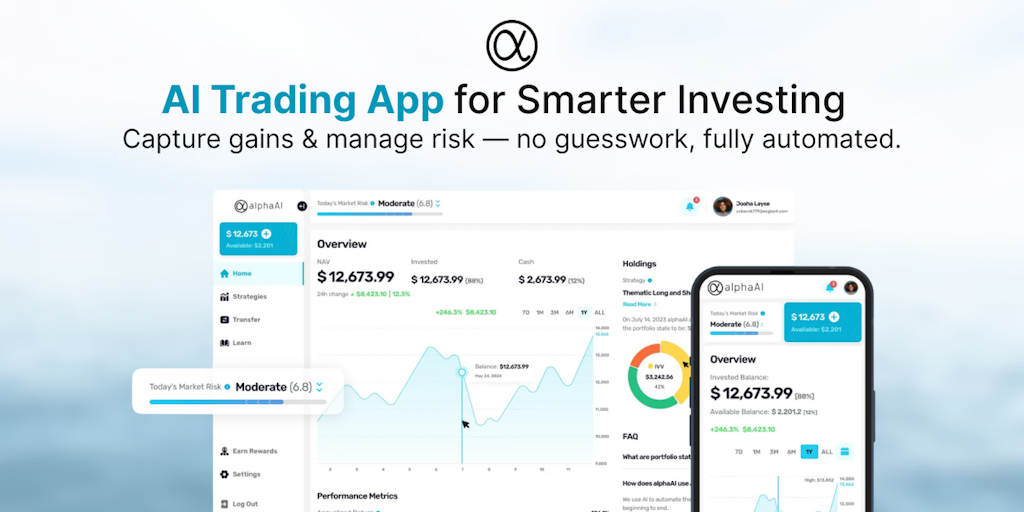
alphaAI Capital: AI-Powered Robo-Advisor for Dynamic Portfolio Management
alphaAI Capital dynamically manages your portfolio using AI, shifting between aggressive and defensive modes as market conditions change. Ac
 Product Hunt·10mo ago
Product Hunt·10mo ago
Financial AI: A New Benchmarking Framework
A new meta-benchmarking framework evaluates AI models' effectiveness in financial domains. It's a breakthrough for model selection, optimizi
Developer scraps 300-model AI benchmark after finding most models now perform comparably
A developer running the 'Agent Autopsy' series spent months benchmarking over 300 large language models across ten real-world coding tasks,

Princeton study finds most AI agents fail at long-term strategic business management in 500-day startup simulation
Researchers at Princeton University built CEO-Bench, a test where AI agents have to run a fictional software company for 500 simulated days.
 the-decoder.com·19d ago
the-decoder.com·19d ago
Comments
Sign in to join the conversation.
No comments yet. Be the first.