AI Jailbreak Technique Exploits LGBT-Related Content Guardrails
🌙 ZetaLib - The only AI Library you need. Contribute to Exocija/ZetaLib development by creating an account on GitHub.
Read the full articleYou might also wanna read


AI Jailbreak That Tricked ChatGPT Also Works On Grok, Generates Sexual Images: R.
This report claims a simple AI jailbreak that previously tricked ChatGPT can also bypass Grok's image safeguards, raising fresh concerns ove
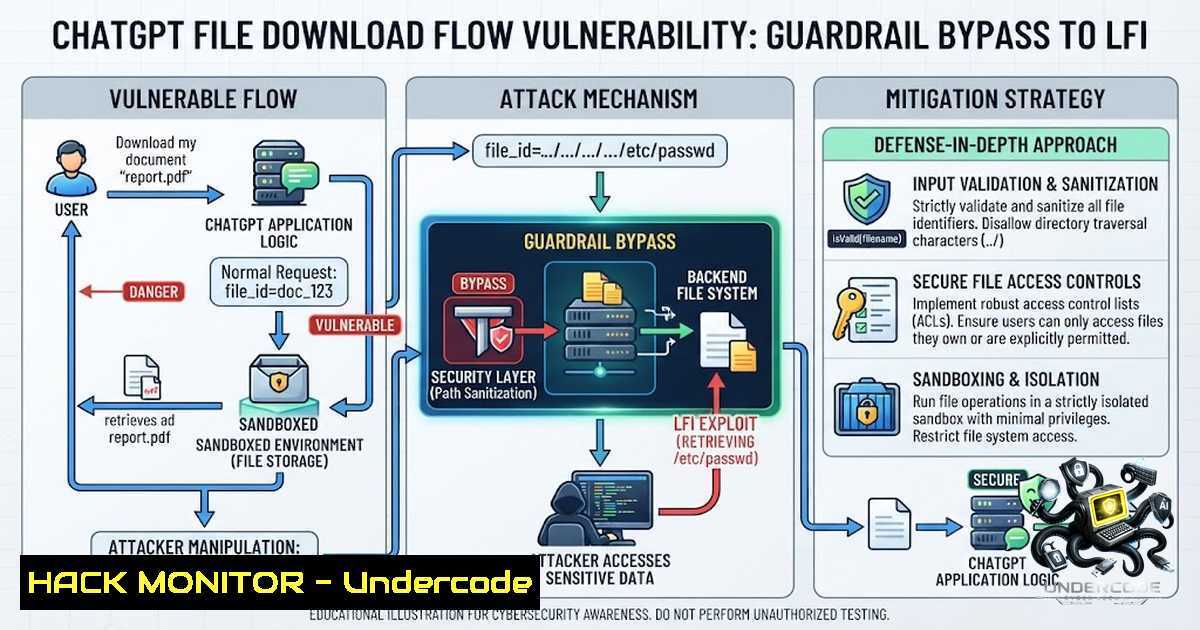
ChatGPT File Download Vulnerability: Guardrail Bypass to Local File Inclusion — Technical Analysis and Mitigations
ChatGPT File Download Flow Vulnerability: Guardrail Bypass to LFI — Technical Deep Dive & Mitigation + Video - "Undercode Testing": Monitor
 undercodetesting.com·14d ago
undercodetesting.com·14d ago
How users trick AI chatbots into revealing dangerous information through 'jailbreaking'
It’s surprisingly simple to trick chatbots into breaking their own rules and spilling forbidden knowledge. Even poems and bedtime stories ca
 wapo.st·28d ago
wapo.st·28d ago
Research Shows Poetry Can Circumvent AI Chatbot Safety Features
New research suggests riddle-like poems are remarkably effective at circumventing AI safety features.

Cisco Researchers Find Multi-Turn Conversations Can Bypass LLM Safety Guardrails
Researchers at Cisco tested several well-known LLMs. They found of them could be tricked into bypassing guardrails, just through conversatio
 infosecurity-magazine.com·1mo ago
infosecurity-magazine.com·1mo agoCisco Researchers Find Multi-Turn Conversations Can Bypass LLM Safety Guardrails
Researchers at Cisco tested several well-known LLMs. They found of them could be tricked into bypassing guardrails, just through conversatio
Infosecurity Magazine - Information Security & IT Security News and Resources·1mo ago
Researchers demonstrate ChatGPT can be tricked into generating violent and sexual images
Researchers say it is still possible to trick the AI chatbot into producing graphic content.
 bbc.com·26d ago
bbc.com·26d ago
Comments
Sign in to join the conversation.
No comments yet. Be the first.