Achieving Top Score on ARC-AGI Benchmark Through Multi-Agent Collaboration and English-Based Reasoning
Using Multi-Agent Collaboration with Evolutionary Test-Time Compute
Read the full articleYou might also wanna read

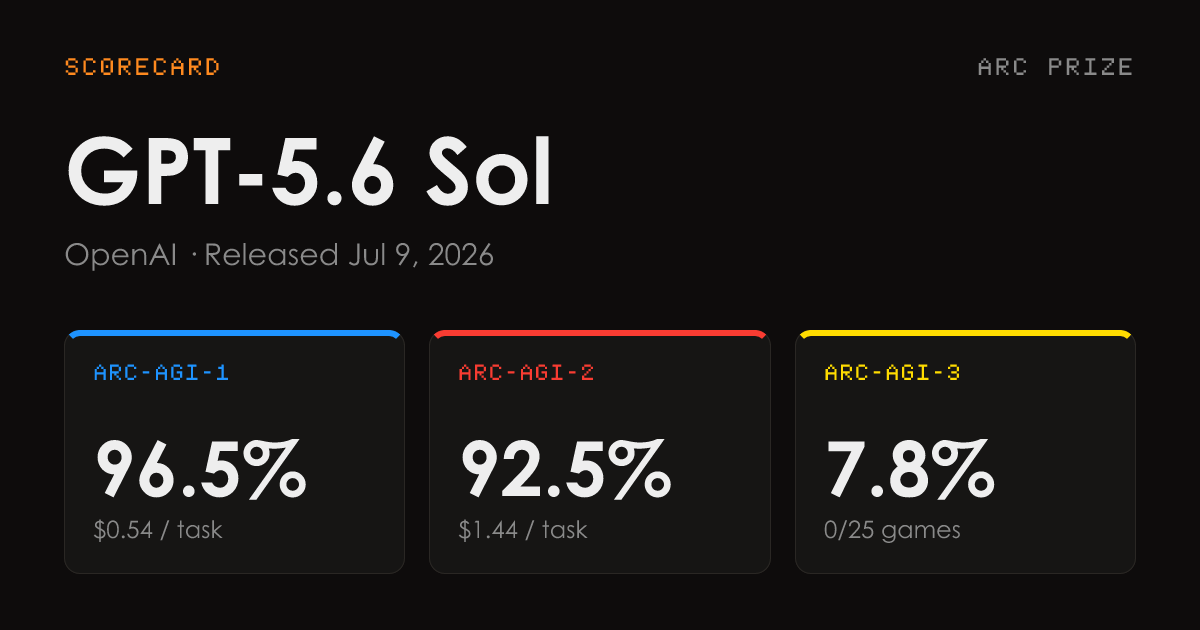
GPT-5.6 Sol Shows Modest Gains on ARC-AGI Reasoning Benchmarks
GPT-5.6 reasoning variants across ARC-AGI-1, ARC-AGI-2, and ARC-AGI-3.
 arcprize.org·7d ago
arcprize.org·7d ago
Fluid Intelligence: AI Benchmarks as Human Tests
A study examines ARC-AGI, initially an AI benchmark, as a measure of human fluid intelligence. The findings show promising psychometric prop

ARCANA: Revolutionizing AGI Task Solving with Multi-Agent Synergy
ARCANA introduces a collaborative multi-agent framework to tackle abstract AGI tasks under stringent constraints. By integrating iterative p
ARC-AGI-3 Benchmark Exposes AI Intelligence Gap
Every frontier AI model scores below 1% on the new ARC-AGI-3 benchmark while humans score 100%. Here's what this means for AI engineers buil

GPT-5.6's Perplexing Performance on ARC-AGI-3: A Milestone or Mirage?
OpenAI's GPT-5.6 has achieved a remarkable 7.8% on the ARC-AGI-3 benchmark, stirring debates regarding its implications for AI's future. Whi
ARC-AGI-2 Explained: The Hardest Public Reasoning Benchmark
ARC-AGI-2 measures fluid intelligence through visual grid puzzles that can't be solved by memorization. Here's how it works, what scores mea
Comments
Sign in to join the conversation.
No comments yet. Be the first.