Shared by @ai-firehose.column.social on Bluesky ↗
Shared by @ai-firehose.column.social on Bluesky ↗ Shared by @ai-firehose.column.social on Bluesky ↗
Shared by @ai-firehose.column.social on Bluesky ↗
 Shared by @jibarrondo.bsky.social on Bluesky ↗
Shared by @jibarrondo.bsky.social on Bluesky ↗ pnas.org4d ago
pnas.org4d ago Shared by @ai-firehose.column.social on Bluesky ↗
Shared by @ai-firehose.column.social on Bluesky ↗ Shared by @ai-firehose.column.social on Bluesky ↗
Shared by @ai-firehose.column.social on Bluesky ↗

The article presents δ-mem, a lightweight memory mechanism for large language models that augments frozen full-attention backbones with a compact online state of associative memory. It compresses past information into a fixed-size state matrix updated by delta-rule learning, gene
This research paper investigates whether Transformer models can learn to predict sequences generated by Permuted Congruential Generators (PCGs), a family of pseudorandom number generators more complex than linear congruential generators (LCGs). The authors demonstrate that Transf


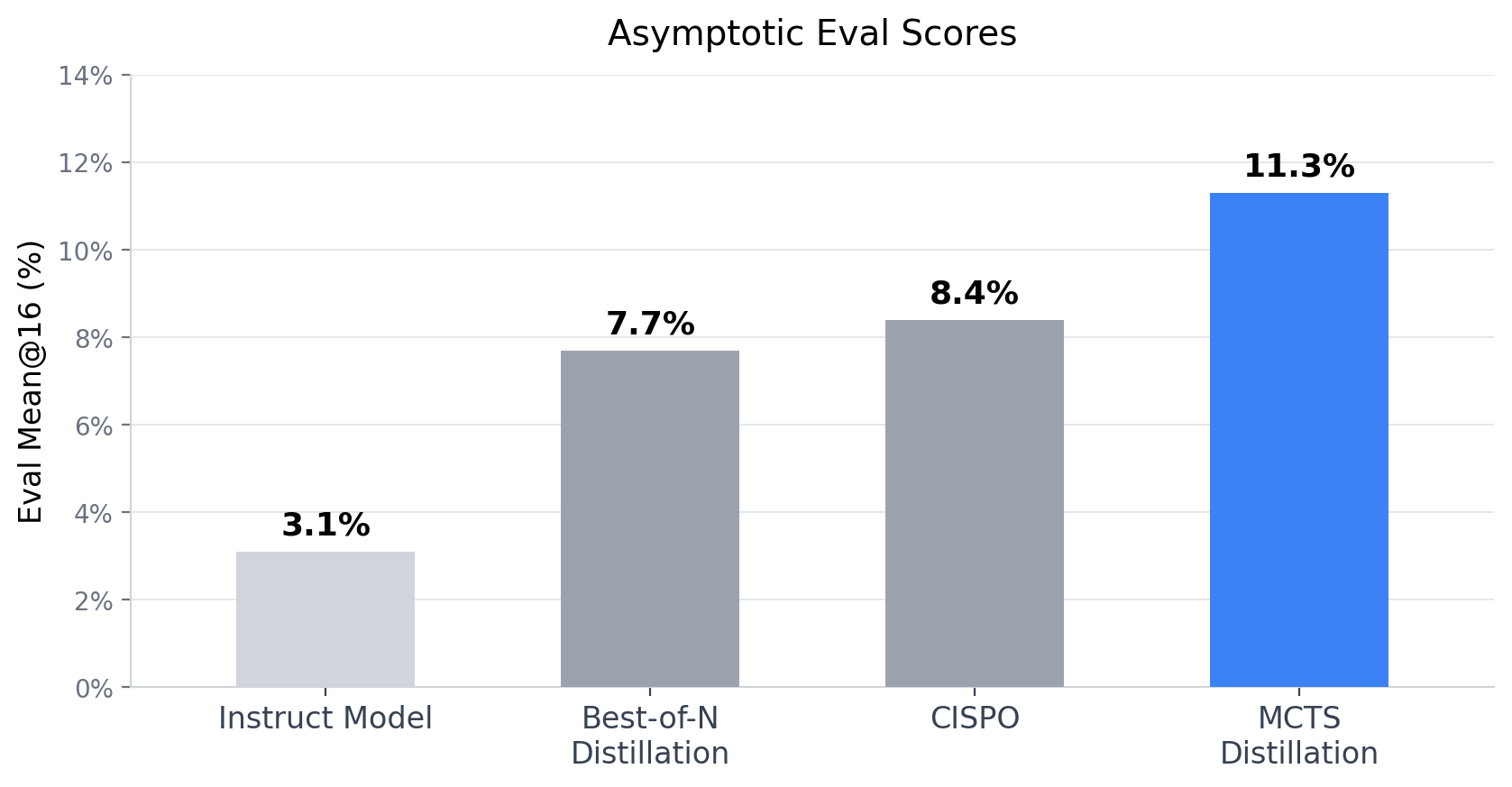

 github.com2mo ago
github.com2mo ago github.com2mo ago
github.com2mo ago