Understanding Spinlocks vs. Mutexes: Performance Trade-offs in Concurrent Programming
By
birdculture
Sesame, salt, and substance. A flagship bake.
Summary
This technical article explores the trade-offs between spinlocks and mutexes for synchronization in concurrent programming. It explains that mutexes put threads to sleep when waiting for a lock, which is efficient for longer critical sections but introduces overhead for very short sections. Spinlocks continuously poll for lock availability, burning CPU cycles but avoiding context-switch overhead, making them suitable for extremely short critical sections. The article provides practical guidance on when to use each primitive based on critical section duration, system load, and hardware characteristics, warning against blindly choosing one over the other without understanding the performance implications.
Key quotes
· 5 pulledMutexes sleep. Spinlocks burn CPU. Both protect your critical section, but they fail in opposite ways.
A mutex that sleeps for 3 microseconds is a disaster when your critical section is 50 nanoseconds.
This is the synchronization primitive trap, and most engineers step right into it because nobody explains when each primitive actually makes sense.
The rule of thumb: if your critical section is shorter than a context switch, spin. If it's longer, sleep.
Spinlocks are for when you're willing to burn CPU to avoid the overhead of putting a thread to sleep and waking it up.
You might also wanna read

Building a Zero-Allocation HTTP/1.1 Parser with OxCaml for High-Performance Research Infrastructure
The article details the development of 'httpz', a high-performance HTTP/1.1 parser built using OxCaml that achieves zero heap allocation. Th
 anil.recoil.org·3mo ago
anil.recoil.org·3mo ago
Implementing Lock-Free Multi-Producer, Multi-Consumer Ring Buffers for High-Performance Systems
The article discusses the implementation and benefits of lock-free multi-producer, multi-consumer (MPMC) ring buffers for high-performance s
 h4x0r.org·5mo ago
h4x0r.org·5mo ago
Restartable Sequences: A Linux Kernel Feature for Lock-Free Thread-Safe Programming
This article explores restartable sequences (rseq), a Linux kernel feature introduced in version 4.18 (circa 2018) that enables creation of
 justine.lol·12h ago
justine.lol·12h ago
Optimizing .NET APIs for High Throughput: Techniques for 1M Requests Per Minute
Article discusses techniques for designing high-throughput .NET APIs capable of handling 1M requests per minute. It covers horizontal scalin
 blog.elmah.io·16h ago
blog.elmah.io·16h ago
How micro-optimizations in Azure Service Bus SDK paved the way for a smarter redesign
The article discusses how micro-optimizations in the Azure Service Bus SDK led to meaningful design improvements. Rather than advocating for
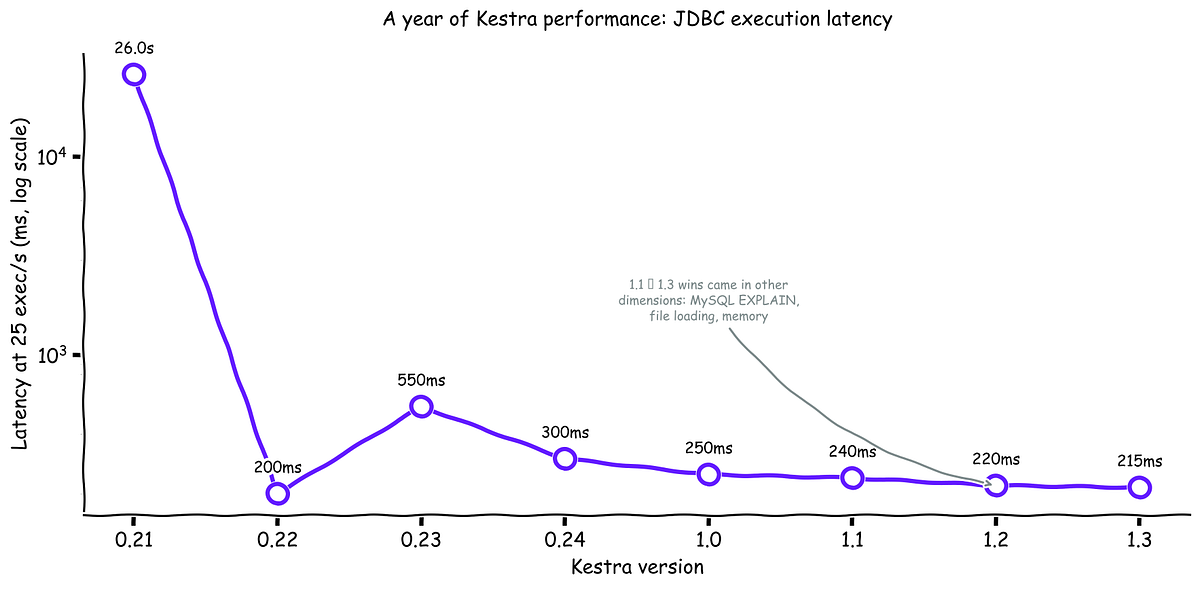
How Kestra Improved Orchestrator Performance Across 14 Releases: A Year of Performance Engineering
Kestra's engineering team details their year-long performance engineering journey across releases 0.19 to 1.3, treating performance as an on
 medium.com·2d ago
medium.com·2d ago