Implementing Lock-Free Multi-Producer, Multi-Consumer Ring Buffers for High-Performance Systems
By
signa11
Pulled from the oven just right. Trustworthy, fact-dense, deeply satisfying.
Summary
The article discusses the implementation and benefits of lock-free multi-producer, multi-consumer (MPMC) ring buffers for high-performance systems, particularly in Linux security environments. It explains how traditional ring buffers are limited to single-reader, single-writer scenarios, while lock-free MPMC ring buffers can handle concurrent access without performance degradation. The content covers the technical challenges of implementing such buffers, including memory ordering, cache line alignment, and avoiding data races, while providing practical solutions for building efficient, scalable data structures that can drop less essential data when overloaded.
Key quotes
· 5 pulledOne of the reasons few security products work well in busy Linux environments is that they amplify performance risk.
In the real world, one of the key ways everyone deals with being overloaded is by dropping less essential things.
We can do the same thing with ring buffers, which are fixed-size queues that typically drop old data once they fill up.
Yet, they rarely get used outside of single-reader, single-writer scenarios.
Fixed-size ring buffers with full lock freedom
You might also wanna read

Building a Zero-Allocation HTTP/1.1 Parser with OxCaml for High-Performance Research Infrastructure
The article details the development of 'httpz', a high-performance HTTP/1.1 parser built using OxCaml that achieves zero heap allocation. Th
 anil.recoil.org·3mo ago
anil.recoil.org·3mo ago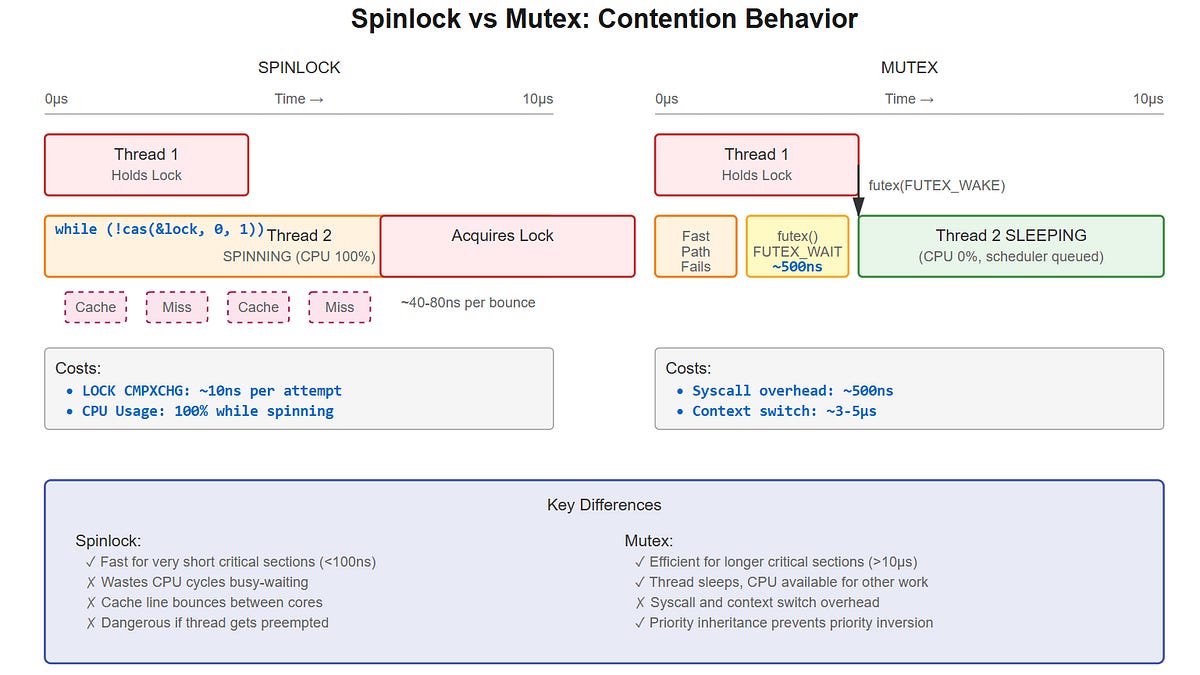
Understanding Spinlocks vs. Mutexes: Performance Trade-offs in Concurrent Programming
This technical article explores the trade-offs between spinlocks and mutexes for synchronization in concurrent programming. It explains that
 howtech.substack.com·5mo ago
howtech.substack.com·5mo ago
Restartable Sequences: A Linux Kernel Feature for Lock-Free Thread-Safe Programming
This article explores restartable sequences (rseq), a Linux kernel feature introduced in version 4.18 (circa 2018) that enables creation of
 justine.lol·16h ago
justine.lol·16h ago
Optimizing .NET APIs for High Throughput: Techniques for 1M Requests Per Minute
Article discusses techniques for designing high-throughput .NET APIs capable of handling 1M requests per minute. It covers horizontal scalin
 blog.elmah.io·20h ago
blog.elmah.io·20h ago
How micro-optimizations in Azure Service Bus SDK paved the way for a smarter redesign
The article discusses how micro-optimizations in the Azure Service Bus SDK led to meaningful design improvements. Rather than advocating for
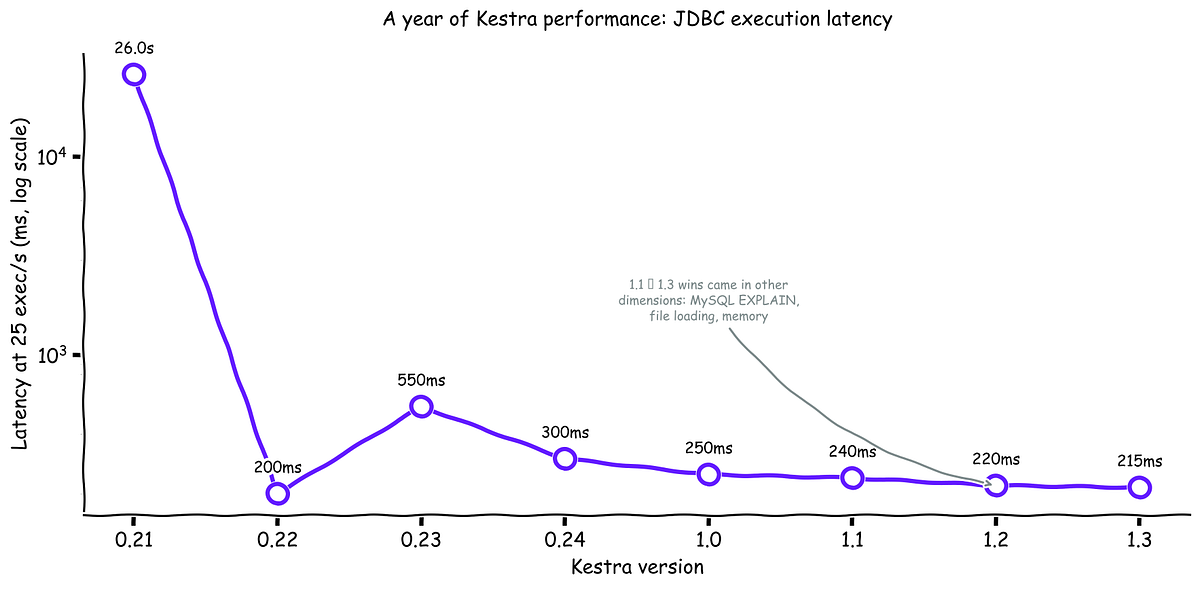
How Kestra Improved Orchestrator Performance Across 14 Releases: A Year of Performance Engineering
Kestra's engineering team details their year-long performance engineering journey across releases 0.19 to 1.3, treating performance as an on
 medium.com·2d ago
medium.com·2d ago