SWE-Bench Pro: Benchmark for Evaluating AI Agents on Software Engineering Tasks
By
tosh
Solid neighbourhood-bakery energy. Trustworthy and warm.
Summary
SWE-Bench Pro is a benchmark dataset designed to evaluate language models and AI agents on long-horizon software engineering tasks. The benchmark requires AI systems to generate patches that resolve issues in codebases, testing their ability to handle complex software engineering problems. The dataset is inspired by SWE-Bench and is available through the Hugging Face datasets library.
Key quotes
· 3 pulledSWE-Bench Pro is a challenging benchmark evaluating LLMs/Agents on long-horizon software engineering tasks
Given a codebase and an issue, a language model is tasked with generating a patch that resolves the described problem
The dataset is inspired from SWE-Bench: https://github.com/SWE-bench/SWE-bench
You might also wanna read

Web Bench: A Comprehensive Benchmark for AI Browser Agent Performance
Web Bench is a new benchmark platform designed to evaluate and compare AI browser agents' performance in web navigation tasks. It provides c
 Product Hunt·1y ago
Product Hunt·1y ago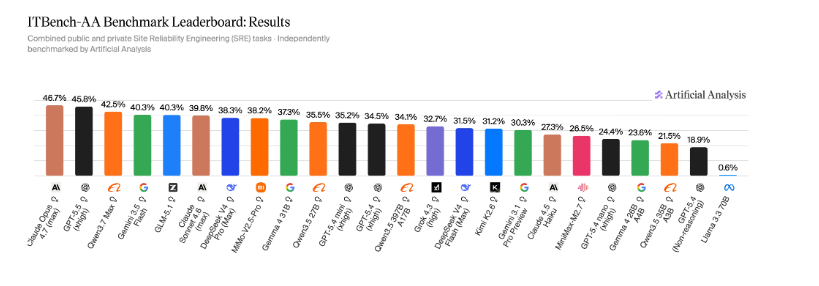
ITBench-AA Benchmark Launched: Frontier AI Models Score Below 50% on Enterprise IT Tasks
Artificial Analysis and IBM Software Innovation Lab have launched ITBench-AA, a new benchmark series evaluating AI models on agentic enterpr
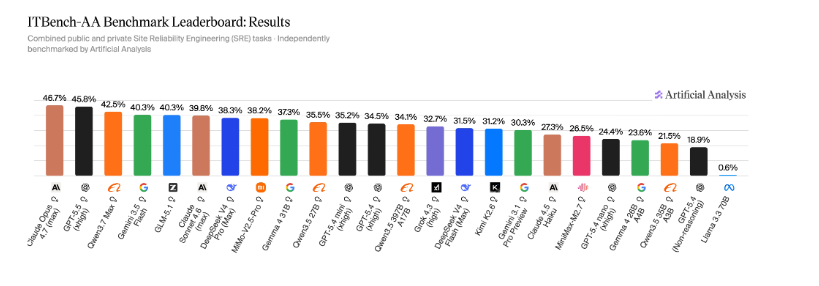
New ITBench-AA Benchmark Reveals AI Models Struggle with Enterprise SRE Tasks
ITBench-AA, a new benchmark developed by Artificial Analysis and IBM Research over six months, reveals that leading AI models like Claude Op