Study Finds Only 16% of AI Benchmarks Use Rigorous Scientific Methods
By
pseudolus
Hot, fresh, and worth queueing round the block for.
Summary
A study from Oxford Internet Institute and other researchers found that only 16% of 445 LLM benchmarks for natural language processing and machine learning use rigorous scientific methods. The research reveals that AI companies often use benchmark results in marketing despite many tests not measuring what they claim to measure, with about half of benchmarks claiming to measure abstract concepts like reasoning or harmlessness without proper validation. The article critiques the current state of AI benchmarking as unreliable and potentially misleading.
Key quotes
· 4 pulledonly 16 percent of 445 LLM benchmarks for natural language processing and machine learning use rigorous scientific methods to compare model performance
about half the benchmarks claim to measure abstract ideas like reasoning or harmlessness without offering proper validation
AI companies regularly tout their models' performance on benchmark tests as a sign of technological and intellectual superiority
those results, widely used in marketing, may not be meaningful
You might also wanna read


Study: Major AI systems from Google, OpenAI, and Anthropic frequently violate EU law in controlled tests
A study from Amsterdam-based AI institute Aithos tested 12 AI models (including systems from Google, OpenAI, and Anthropic) across roughly 1
 dlvr.it·2d ago
dlvr.it·2d ago
Amazon's AI Chief Criticizes Benchmark Obsession, Emphasizes Real-World Utility
Amazon's AI chief Rohit Prasad argues that AI model benchmarks and leaderboards are misleading and don't reflect real-world utility. He crit

Major AI models fail EU legal compliance tests, Aithos study finds
Nonprofit AI research foundation Aithos developed a tool called LARA (Legal Assessment for Real-world Agents) to evaluate AI models' complia
 theregister.com·4d ago
theregister.com·4d ago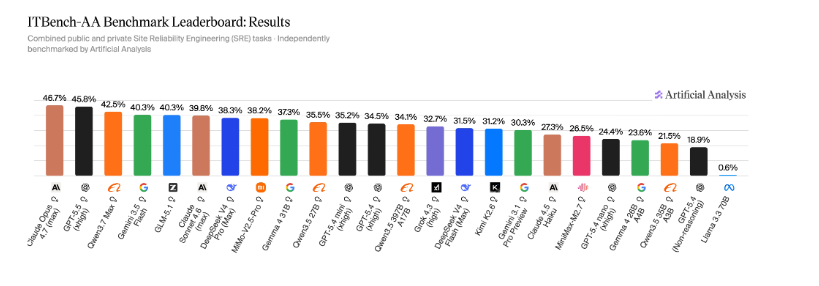
New ITBench-AA Benchmark Reveals AI Models Struggle with Enterprise SRE Tasks
ITBench-AA, a new benchmark developed by Artificial Analysis and IBM Research over six months, reveals that leading AI models like Claude Op
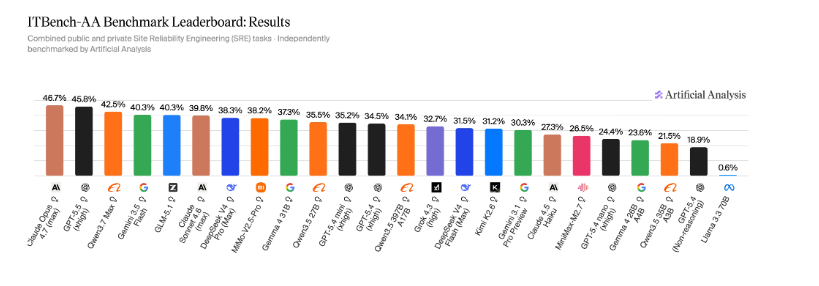
ITBench-AA Benchmark Launched: Frontier AI Models Score Below 50% on Enterprise IT Tasks
Artificial Analysis and IBM Software Innovation Lab have launched ITBench-AA, a new benchmark series evaluating AI models on agentic enterpr

Study Finds Frontier AI Models Disagree on Two-Thirds of Basic Fact-Check Claims
A new study by researcher Kosta Jordanov at Lenz Research tested five frontier AI models (GPT-5.4, Claude Opus 4.7, Gemini 3 Pro, Gemini 3 P
 decrypt.co·2d ago
decrypt.co·2d ago