RL-Index: A Reinforcement Learning Framework for Shifting Retrieval Reasoning to the Indexing Stage
By
[Submitted on 15 Jun 2026]
Crispy enough to crunch, soft enough to enjoy. A good bake.
Summary
This paper introduces RL-Index, a novel agentic indexing framework that reframes retrieval index reasoning as a reinforcement learning problem. Unlike traditional query-side reasoning approaches (e.g., query rewriting) that introduce online latency, RL-Index shifts reasoning to the indexing stage by augmenting documents with LLM-generated rationales that encode latent query-knowledge relationships. The framework uses Group Relative Policy Optimization (GRPO) with retrieval similarity as a verifiable reward signal to optimize rationale quality. Experiments on the BRIGHT benchmark show RL-Index improves both retrieval and downstream QA performance while significantly reducing online inference latency, and the approach generalizes across different retrievers and generators.
Key quotes
· 5 pulledRetrieving external knowledge is essential for solving real-world tasks, yet it remains challenging when the relationship between a query and its relevant knowledge involves implicit and complex reasoning beyond surface-level semantic or lexical matching.
We propose RL-Index, an agentic indexing framework that formulates retrieval index reasoning as a reinforcement learning problem.
Instead of performing reasoning at query time, RL-Index shifts reasoning to the indexing stage by augmenting documents with LLM-generated rationales that explicitly encode the latent query-knowledge relationship.
To optimize the quality of these rationales, we employ Group Relative Policy Optimization (GRPO) and use retrieval similarity as a verifiable reward signal, enabling direct optimization of indexing decisions for retrieval effectiveness.
The learned rationale augmentation generalizes across diverse retrievers and generators, highlighting its robustness as a plug-and-play indexing strategy across different retrieval systems.
You might also wanna read

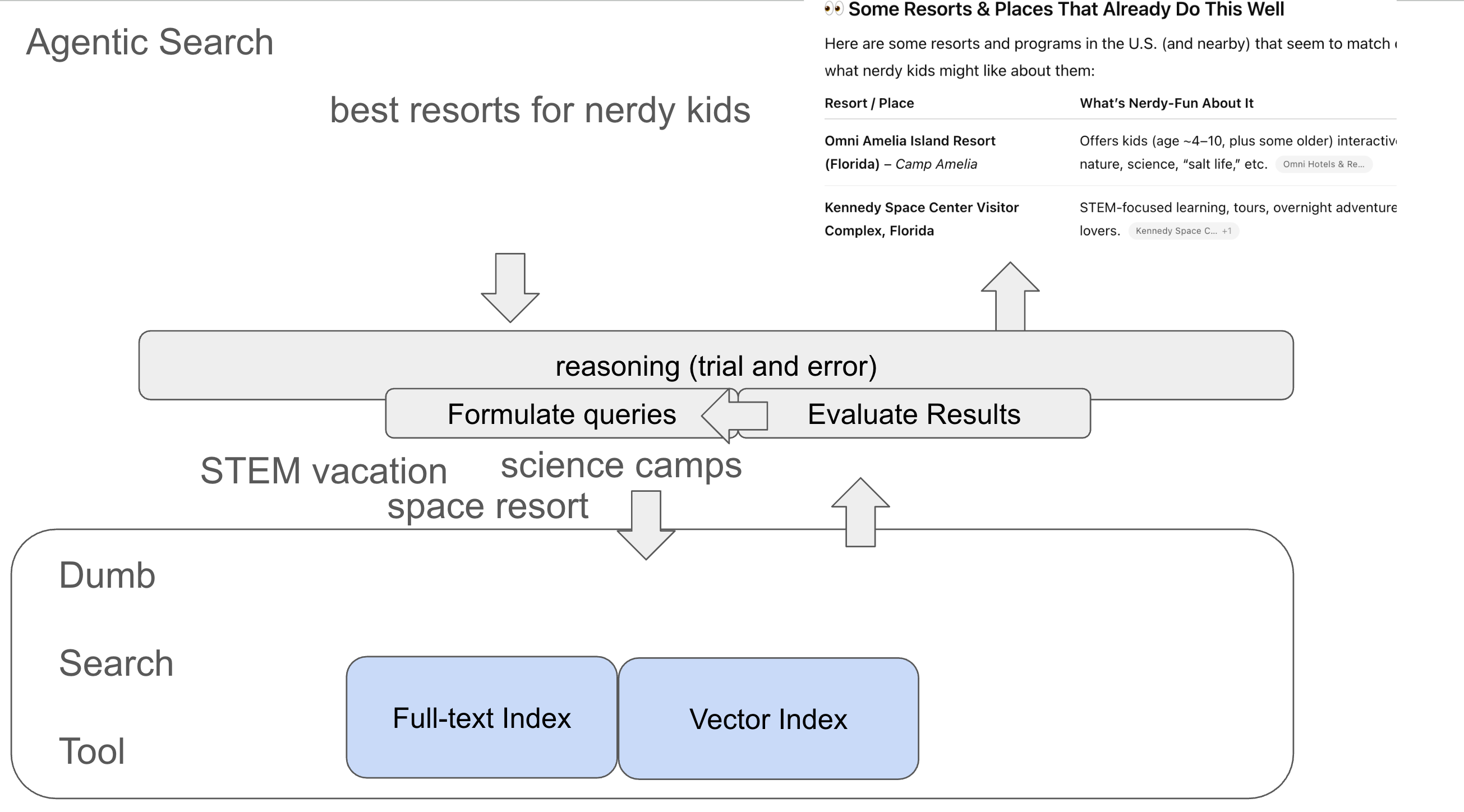
How AI agents are evolving RAG systems from keyword search to iterative, reasoning-based search experiences
The article discusses how AI agents are transforming traditional RAG (Retrieval-Augmented Generation) systems by moving beyond simple keywor
 softwaredoug.com·8mo ago
softwaredoug.com·8mo ago
Direct Corpus Interaction: A New Retrieval Paradigm for Agentic Search Without Embedding Models
This research paper introduces Direct Corpus Interaction (DCI), a novel approach to retrieval for agentic search that bypasses traditional e

Chroma Context-1: A 20B Parameter Agentic Search Model for Multi-Hop Retrieval
Chroma Context-1 is a 20B parameter agentic search model designed to improve retrieval-augmented generation (RAG) systems. Unlike traditiona
 trychroma.com·2mo ago
trychroma.com·2mo ago
Tenure: A local AI memory system that stores both facts and actionable instructions for LLMs
Tenure is a local AI memory system that goes beyond storing facts by also storing instructions on what to do with those facts. Unlike most L
 Product Hunt·1mo ago
Product Hunt·1mo ago
Meta Superintelligence Labs' First Paper Focuses on Retrieval-Augmented Generation (RAG)
Meta Superintelligence Labs' first published paper focuses on Retrieval-Augmented Generation (RAG) rather than expected model layer innovati
 paddedinputs.substack.com·8mo ago
paddedinputs.substack.com·8mo ago
Rethinking Search: From Query-Answer Services to Programmable Primitives for AI Agents
The article argues that traditional search pipelines are becoming outdated for AI agent systems. It proposes rethinking search as a programm
 research.perplexity.ai·13d ago
research.perplexity.ai·13d ago