PerspectiveGap: A New Benchmark Reveals LLMs Struggle with Multi-Agent Orchestration Prompting
By
[Submitted on 7 Jun 2026]
Reliable enough to start your morning with. Toast it again tomorrow.
Summary
The article introduces PerspectiveGap, a benchmark designed to evaluate LLMs' ability to compose orchestration prompts for multi-agent systems. It contains 110 scenarios across 10 topologies, tested via role-fragment assignment and free-form prompt writing. Experiments with 27 commercial models show GPT-5.5 significantly outperforms competitors, but overall performance remains low (14.9% average pass rate), indicating multi-agent orchestration prompting is a distinct and under-evaluated capability.
Key quotes
· 4 pulledReal-world LLM applications are moving beyond single-agent workflows toward orchestrated multi-agent systems, yet current models still struggle to determine what each sub-agent needs to know.
PerspectiveGap contains 110 scenarios, each evaluated through two distractor-mixed task formats: role-fragment assignment and free-form prompt writing.
the evaluated models achieve an average combined pass rate of only 14.9% (GPT-5.5 62.0%) and an average overall leakage rate of 246.5%
These findings suggest that multi-agent orchestration prompting is a distinct and under-evaluated capability, and PerspectiveGap provides a foundation for measuring and improving it systematically.
You might also wanna read


SkillsBench: A Benchmark for Evaluating AI Agent Skills Across Diverse Tasks
SkillsBench is a new benchmark for evaluating how well AI agent skills work across diverse tasks. The benchmark includes 86 tasks across 11
Achieving Top Score on ARC-AGI Benchmark Through Multi-Agent Collaboration and English-Based Reasoning
The author discusses achieving the highest score on the ARC-AGI benchmark by using multi-agent collaboration with evolutionary test-time com

The Evolution of LLM Customization: From Simple Prompts to Complex Agent Systems
The article examines the evolution of LLM (Large Language Model) customization and extension mechanisms over the past three years, tracing t

Meta-harness optimization loop on Islo: A 200-line POC for automated LLM agent improvement
A 200-line proof-of-concept demonstrating a meta-harness optimization loop built on Islo sandboxes. The system uses a proposer agent that re
 zozo123.github.io·1mo ago
zozo123.github.io·1mo ago
Gas Town Agent Orchestrator: Examining Design Bottlenecks and Vibecoding at Scale
The article discusses Steve Yegge's 'Gas Town' agent orchestrator system, which runs dozens of coding agents simultaneously in a metaphorica
 maggieappleton.com·4mo ago
maggieappleton.com·4mo ago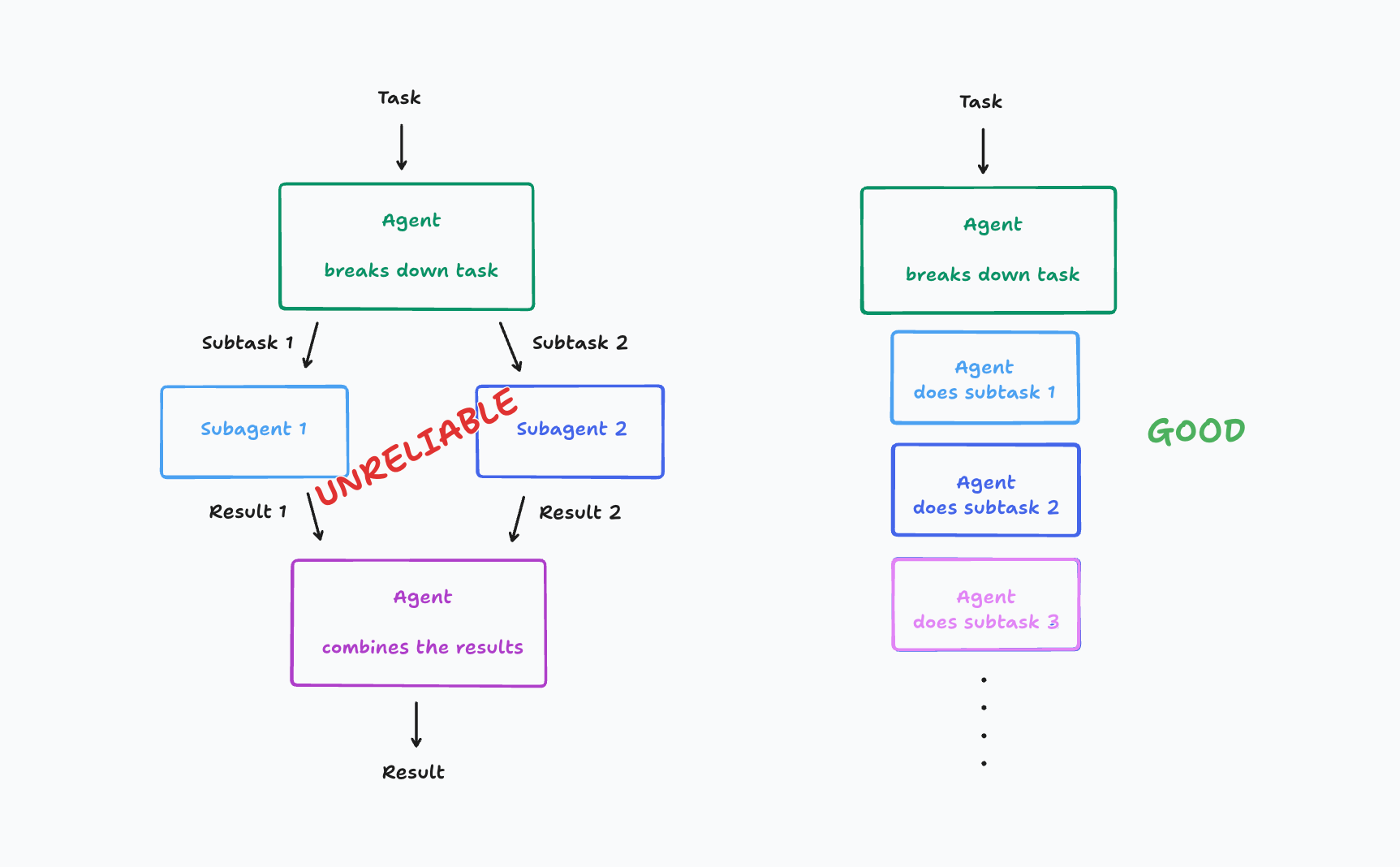
Principles for Effective LLM Agent Development: Avoiding Multi-Agent Pitfalls
The article critiques current LLM agent frameworks and proposes principles for building effective agents based on the author's practical exp
 cognition.ai·9mo ago
cognition.ai·9mo ago