Oxford-led study finds AI evaluation benchmarks lack scientific rigor
By
pseudolus
A five-star bake. Worth schmearing, sharing, saving.
Summary
A comprehensive study led by Oxford Internet Institute involving 42 researchers from leading global institutions found that many tests used to evaluate large language models lack scientific rigor. The research, which represents the largest systematic review of AI benchmarks, highlights issues with construct validity in LLM evaluations, calling for clearer definitions and stronger scientific standards in AI assessment methodologies.
Key quotes
· 3 pulledA new study led by the Oxford Internet Institute (OII) at the University of Oxford and involving a team of 42 researchers from leading global institutions has found that many of the tests used to measure the capabilities and safety of large language models (LLMs) lack scientific rigour.
Measuring What Matters: Construct Validity in Large Language Model Benchmarks, accepted for publication in the upcoming Neur
Largest systematic review of AI benchmarks highlights need for clearer definitions and stronger scientific standards.
You might also wanna read


Major AI models fail EU legal compliance tests, Aithos study finds
Nonprofit AI research foundation Aithos developed a tool called LARA (Legal Assessment for Real-world Agents) to evaluate AI models' complia
 theregister.com·4d ago
theregister.com·4d ago
Study: Major AI systems from Google, OpenAI, and Anthropic frequently violate EU law in controlled tests
A study from Amsterdam-based AI institute Aithos tested 12 AI models (including systems from Google, OpenAI, and Anthropic) across roughly 1
 dlvr.it·2d ago
dlvr.it·2d ago
Study Finds Frontier AI Models Disagree on Two-Thirds of Basic Fact-Check Claims
A new study by researcher Kosta Jordanov at Lenz Research tested five frontier AI models (GPT-5.4, Claude Opus 4.7, Gemini 3 Pro, Gemini 3 P
 decrypt.co·2d ago
decrypt.co·2d ago
AI and Publish-or-Perish Culture Are Overwhelming Academic Peer Review, Study Finds
This article, authored by the AI Task Force for Organization Science, examines how generative AI is reshaping academic peer review and resea

Amazon's AI Chief Criticizes Benchmark Obsession, Emphasizes Real-World Utility
Amazon's AI chief Rohit Prasad argues that AI model benchmarks and leaderboards are misleading and don't reflect real-world utility. He crit
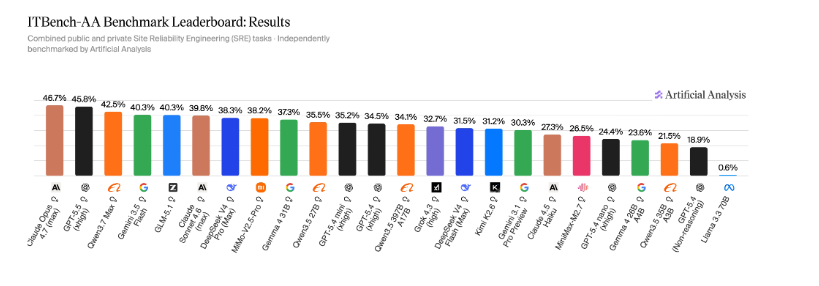
New ITBench-AA Benchmark Reveals AI Models Struggle with Enterprise SRE Tasks
ITBench-AA, a new benchmark developed by Artificial Analysis and IBM Research over six months, reveals that leading AI models like Claude Op