ntransformer: C++/CUDA LLM Inference Engine Enables Running Llama 70B on RTX 3090
By
xaskasdf
Pure flour-power. Hearty enough to carry you through lunch.
Summary
ntransformer is a high-efficiency C++/CUDA LLM inference engine that enables running large language models like Llama 70B on consumer-grade hardware like the RTX 3090 (24GB VRAM). The engine uses innovative memory management techniques including streaming model layers through GPU memory via PCIe and optional NVMe direct I/O that bypasses the CPU entirely. Performance results show the system can run Llama 3.1 8B Q8_0 models at 48.9 tokens/second with all layers resident in VRAM, and can handle much larger 70B models through tiered memory management that combines VRAM, RAM, and NVMe storage.
Key quotes
· 4 pulledHigh-efficiency C++/CUDA LLM inference engine. Runs Llama 70B on a single RTX 3090 (24GB VRAM) by streaming model layers through GPU memory via PCIe, with optional NVMe direct I/O that bypasses the CPU entirely.
Llama 3.1 8B Q8_0 Resident: 48.9 tok/s, 10.0 GB - All layers in VRAM
Llama 3.1 70B Q6_K Tiered (auto): 0.2 tok/s, 23.1 GB - 26 VRAM + 54 RAM + 0 NVMe
High-efficiency LLM inference engine in C++/CUDA. Run Llama 70B on RTX 3090.
You might also wanna read


RTP-LLM: Alibaba's High-Performance Inference Engine for Large Language Model Deployment
This paper presents RTP-LLM, a high-performance inference engine developed by Alibaba for industrial-scale deployment of Large Language Mode
Guide to Calculating GPU Memory for Self-Hosted LLM Inference
The article provides a guide on calculating GPU memory requirements and managing concurrent requests for self-hosted large language model (L
 Product Hunt·9mo ago
Product Hunt·9mo ago
EXO Labs Runs Llama 2 AI Model on 1997 Pentium II Using BitNet Optimization
EXO Labs successfully ran a lightweight Llama 2 AI model on a 1997 Pentium II processor with only 128 MB of RAM by leveraging BitNet's terna
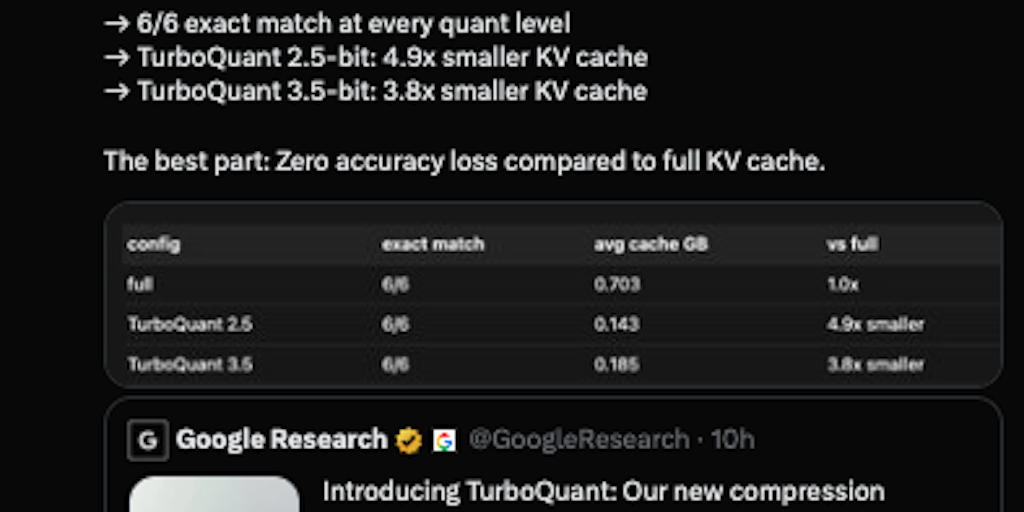
Google Introduces TurboQuant: Advanced LLM Compression Algorithm for Efficient AI Model Deployment
Google has developed TurboQuant, a new LLM compression algorithm that uses advanced theoretically grounded quantization techniques to enable
 Product Hunt·2mo ago
Product Hunt·2mo ago