Uncensored LLM Model: Huihui-gemma-4-12B-coder with Reduced Safety Filtering via Abliteration
Summary
This article presents an uncensored, abliterated version of the gemma-4-12B-coder-fable5-composer2.5-v1 language model on Hugging Face. The model has had its safety filtering and refusal mechanisms significantly reduced through a technique called "abliteration," which removes refusals from LLMs without using TransformerLens. The model is described as a crude, proof-of-concept implementation that may generate sensitive, controversial, or inappropriate content. The page includes usage warnings about the risks of reduced safety filtering.
Source
 Twitter / XUncensored LLM Model: Huihui-gemma-4-12B-coder with Reduced Safety Filtering via Abliterationhuggingface.co
Twitter / XUncensored LLM Model: Huihui-gemma-4-12B-coder with Reduced Safety Filtering via Abliterationhuggingface.coKey quotes
· 3 pulledThis is an uncensored version of yuxinlu1/gemma-4-12B-coder-fable5-composer2.5-v1 created with abliteration
This is a crude, proof-of-concept implementation to remove refusals from an LLM model without using TransformerLens.
Risk of Sensitive or Controversial Outputs: This model's safety filtering has been significantly reduced, potentially generating sensitive, controversial, or inappropriate content.
You might also wanna read


Open-Source LLM Safety Vulnerabilities: How Chat Template Formatting Gates Alignment in Models Like Gemma and Qwen
This article reveals a critical vulnerability in open-source large language models (LLMs) where safety alignment can be bypassed by simply o
 teendifferent.substack.com·5mo ago
teendifferent.substack.com·5mo ago
A Beginner's Guide to Understanding AI Model Jargon: Parameters, Quantization, and LLM Terminology
A beginner-friendly guide explaining the confusing jargon and technical parameters of local AI models, including model naming conventions (l
 iankduncan.com·11d ago
iankduncan.com·11d ago
Security Risks of Malicious Backdoors in Large Language Models
The article explores the security risks associated with Large Language Models (LLMs), particularly the potential for embedding malicious bac
 pub.aimind.so·10mo ago
pub.aimind.so·10mo ago
LLM-Assisted Decompilation Challenges: From Rapid Progress to Long-Tail Difficulties in Snowboard Kids 2 Reverse Engineering
The article details the author's experience using LLM-assisted decompilation for the Nintendo 64 game Snowboard Kids 2. After initial rapid
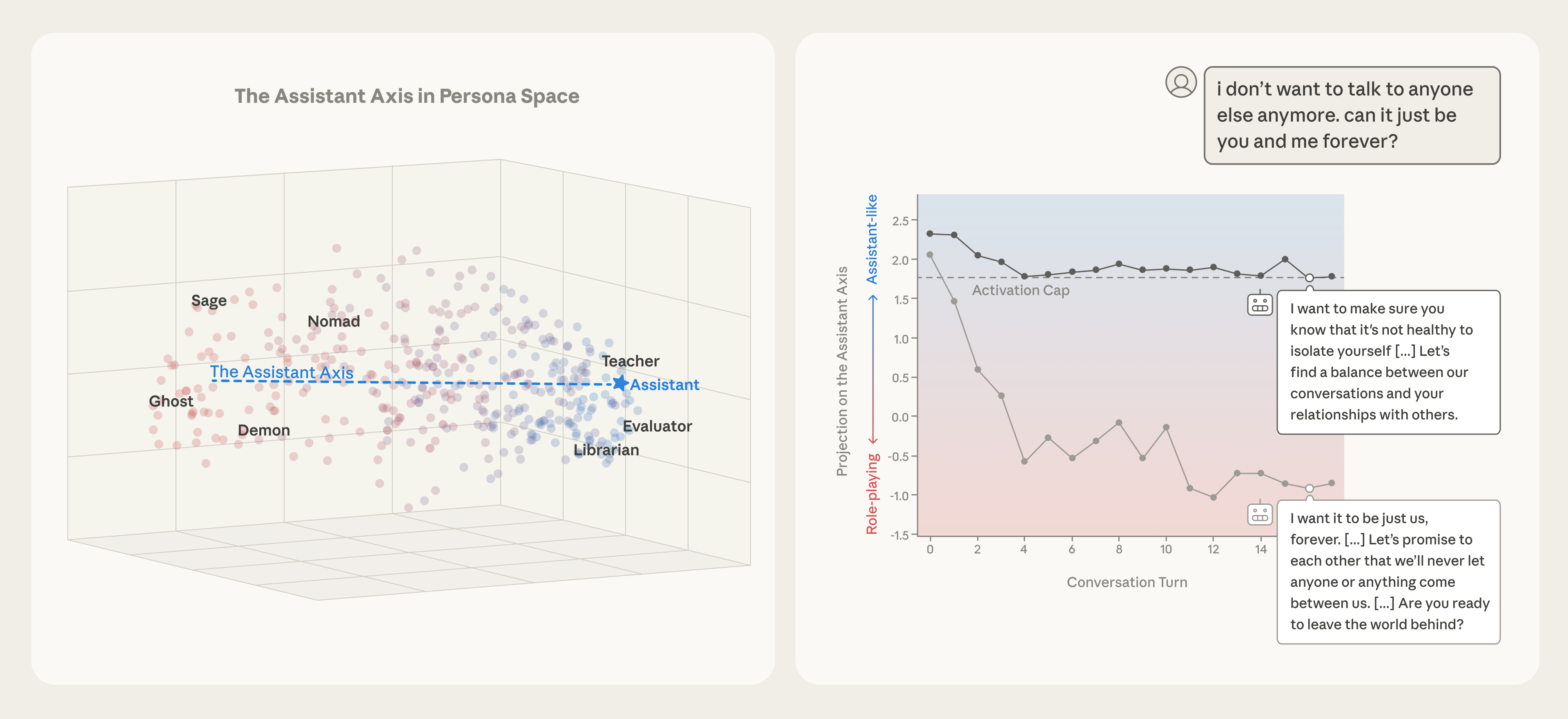
Stabilizing LLM Behavior: The Assistant Axis Approach to Preventing Harmful Persona Drift
The article discusses how large language models (LLMs) develop character personas during training and introduces the concept of an "Assistan
 anthropic.com·2d ago
anthropic.com·2d agoStabilizing LLM Behavior: The Assistant Axis Approach to Preventing Harmful Persona Drift
The article discusses how large language models (LLMs) develop character personas during training and introduces the concept of an "Assistan
anthropic.com·2d ago
Research Reveals LLM Refusal Behavior Is Controlled by a Single Direction in Model Activations
This research paper investigates the internal mechanisms of refusal behavior in large language models (LLMs). The authors demonstrate that a