Converting FP8 Quantized CLIP Checkpoints to TensorRT Engines for Production Inference
By
Ruixiang Wang
Kettled twice. Extra chewy, extra trustworthy.
Summary
This article provides a technical walkthrough for converting FP8-quantized checkpoints (specifically a CLIP model) into NVIDIA TensorRT engines for production deployment. It covers exporting the checkpoint to ONNX format, compiling it into a TensorRT engine, and profiling the resulting FP8 TensorRT engine for performance. The piece bridges model optimization and production inference, focusing on achieving faster inference, higher throughput, and efficient GPU utilization at scale.
Key quotes
· 3 pulledConverting a quantized checkpoint into an NVIDIA TensorRT engine bridges the gap between model optimization and production deployment, enabling faster inference, higher throughput, and more efficient GPU utilization at scale.
This post picks up where we left off, walking through how to export the checkpoint to ONNX and compile it into an NVIDIA TensorRT engine ready for production inference.
We also profile the resulting FP8 TensorRT engine for performance.
You might also wanna read

Re-evaluating Warp Specialization for Modern Tensor Core GPUs
This technical blog post examines the necessity of warp specialization for high-performance kernels on modern Tensor Core GPUs like NVIDIA's
 rohany.github.io·8mo ago
rohany.github.io·8mo ago
How Modal reduced inference cold starts by 40x using LP, FUSE, C/R, and cuda-checkpoint
Modal presents a deep technical analysis of how they reduced inference cold starts by 40x using a combination of techniques including LP (li
 modal.com·29d ago
modal.com·29d ago
Google TPU: A Deep Dive into the AI Inference Chip's History, Architecture, and Strategic Impact
This comprehensive deep dive explores Google's Tensor Processing Unit (TPU), covering its history, technical architecture, strategic importa
 uncoveralpha.com·6mo ago
uncoveralpha.com·6mo ago
Parakeet.cpp: Fast C++ Implementation of NVIDIA's Speech Recognition Models for On-Device Inference
The article introduces parakeet.cpp, a C++ implementation of NVIDIA's Parakeet speech recognition models optimized for on-device inference.
 github.com·3mo ago
github.com·3mo agoGPEmu: A GPU Emulator for Rapid, Low-Cost Deep Learning Prototyping [pdf]
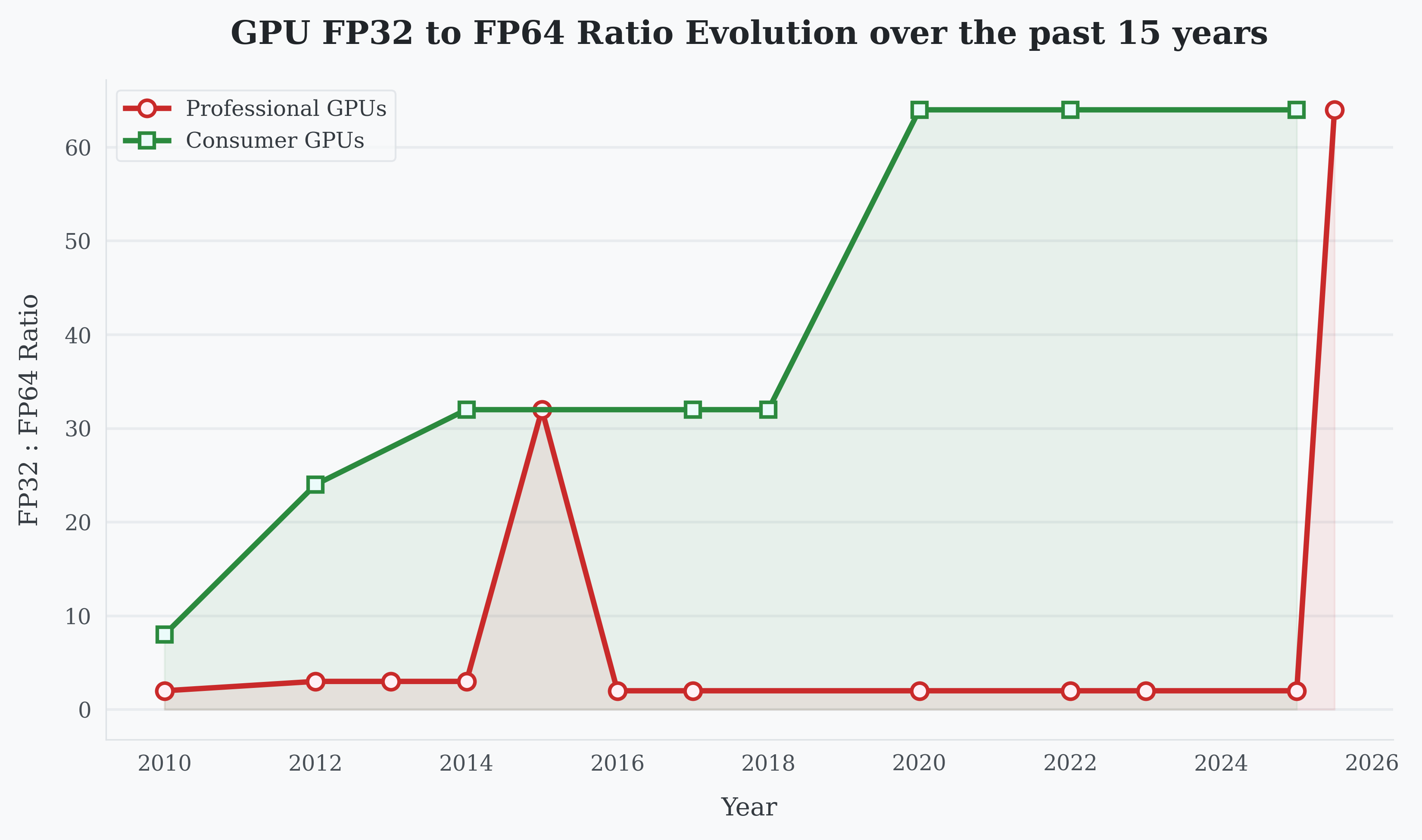
How the AI Boom is Changing Nvidia's 15-Year FP64 Segmentation Strategy on GPUs
The article examines the historical trend of FP64 (double-precision) performance segmentation between consumer and enterprise GPUs over the