Parakeet.cpp: Fast C++ Implementation of NVIDIA's Speech Recognition Models for On-Device Inference
By
noahkay13
Crisp on the outside, thoughtful on the inside. A keeper.
Summary
The article introduces parakeet.cpp, a C++ implementation of NVIDIA's Parakeet speech recognition models optimized for on-device inference. It uses the Axiom tensor library for automatic Metal GPU acceleration on Apple Silicon, achieving significant performance improvements over CPU inference. The implementation eliminates dependencies on Python and ONNX runtime, offering ultra-fast inference times (27ms for 10-second audio on Apple Silicon GPU) and memory efficiency with FP16 support. It supports multiple Parakeet models including English and multilingual variants for offline speech recognition.
Key quotes
· 5 pulledFast speech recognition with NVIDIA's Parakeet models in pure C++
Built on axiom — a lightweight tensor library with automatic Metal GPU acceleration
No ONNX runtime, no Python runtime, no heavyweight dependencies. Just C++ and one tensor library that outruns PyTorch MPS
~27ms encoder inference on Apple Silicon GPU for 10s audio (110M model) — 96x faster than CPU
FP16 support for ~2x memory reduction
You might also wanna read


Ringg launches Parrot: A speech-to-text model optimized for noisy, Hindi-heavy voice agent conversations
Ringg introduces Parrot, a speech-to-text model specifically designed for production-grade voice agents. Unlike standard STT models that per
 Product Hunt·6d ago
Product Hunt·6d ago
MiniCPM 4.0: Ultra-Efficient Open-Source AI Models for On-Device Deployment
MiniCPM 4.0 is a family of ultra-efficient, open-source AI models designed for on-device deployment, offering significant speed improvements
Product Hunt·11mo ago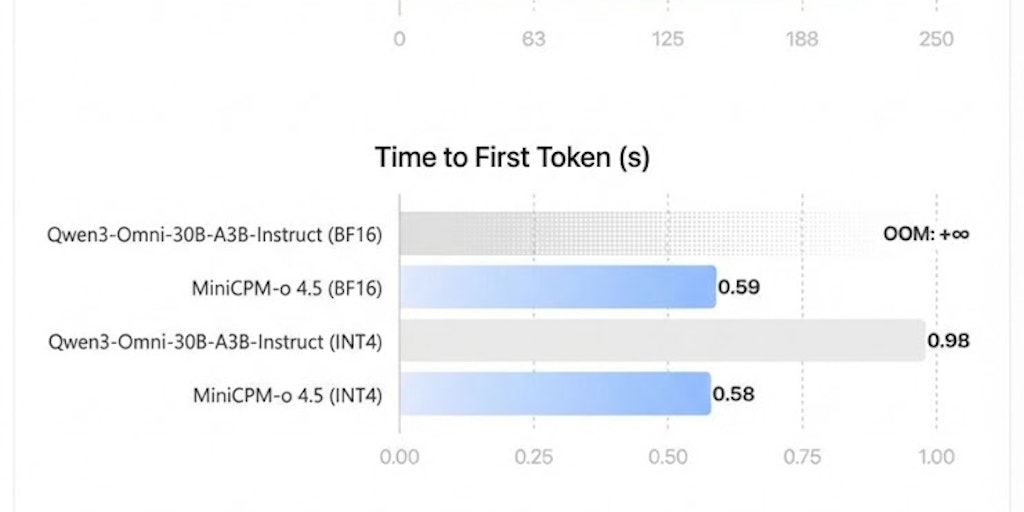
MiniCPM 4.0: Ultra-Efficient Open-Source AI Models for On-Device Deployment
MiniCPM 4.0 is a family of ultra-efficient, open-source AI models designed for on-device deployment, offering significant speed improvements
Product Hunt·6d ago