Latent Agents: Distilling Multi-Agent Debate into Single LLMs via Post-Training Internalization
By
[Submitted on 27 Apr 2026]
Reliable enough to start your morning with. Toast it again tomorrow.
Summary
This paper introduces "Latent Agents," a post-training framework that distills multi-agent debate into a single LLM through a two-stage fine-tuning pipeline. The approach combines debate structure learning with internalization via dynamic reward scheduling and length clipping. Results show the internalized models match or exceed explicit multi-agent debate performance while using up to 93% fewer tokens. The research investigates the mechanistic basis through activation steering, finding that internalization creates agent-specific subspaces in activation space. A practical application demonstrates that instilling malicious agents and applying negative steering makes harmful behaviors easier to localize and control with smaller performance reductions compared to steering base models.
Key quotes
· 5 pulledMulti-agent debate has been shown to improve reasoning in large language models (LLMs). However, it is compute-intensive, requiring generation of long transcripts before answering questions.
Our internalized models match or exceed explicit multi-agent debate performance using up to 93% fewer tokens.
We investigate the mechanistic basis of this capability through activation steering, finding that internalization creates agent-specific subspaces: interpretable directions in activation space corresponding to different agent perspectives.
By instilling malicious agents into the LLM through internalized debate, then applying negative steering to suppress them, we show that distillation makes harmful behaviors easier to localize and control with smaller reductions in general performance compared to steering base models.
Our findings offer a new perspective for understanding multi-agent capabilities in distilled models and provide practical guidelines for controlling internalized reasoning behaviors.
You might also wanna read


Applying Distributed Systems Theory to Large Language Model Teams
The article proposes using distributed systems theory as a principled framework for creating and evaluating teams of large language models (

Research Reveals LLMs Contain Built-In Persona Subnetworks Without External Training
This research paper reveals that large language models (LLMs) already contain specialized persona subnetworks within their parameter space,
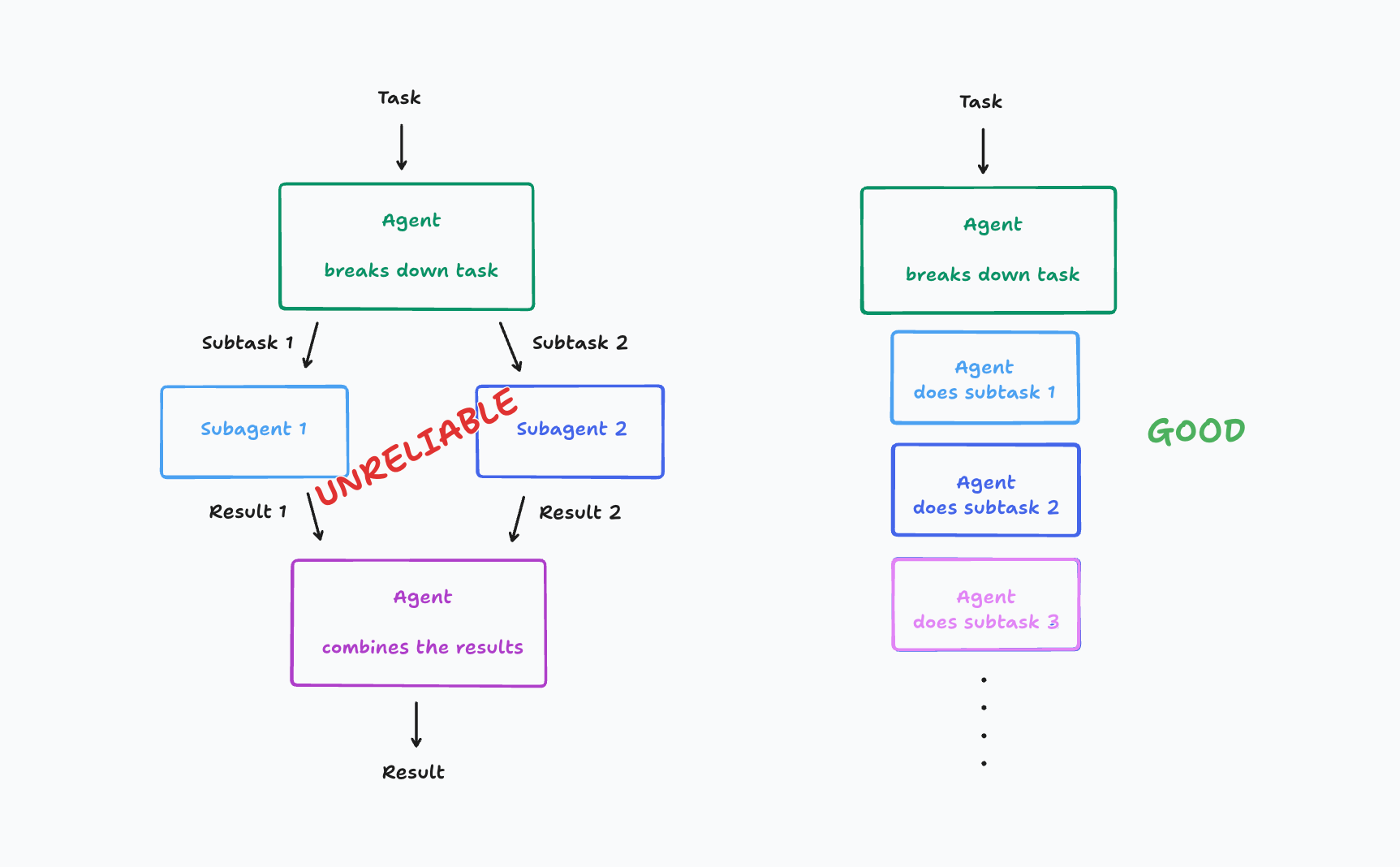
Principles for Effective LLM Agent Development: Avoiding Multi-Agent Pitfalls
The article critiques current LLM agent frameworks and proposes principles for building effective agents based on the author's practical exp
 cognition.ai·9mo ago
cognition.ai·9mo ago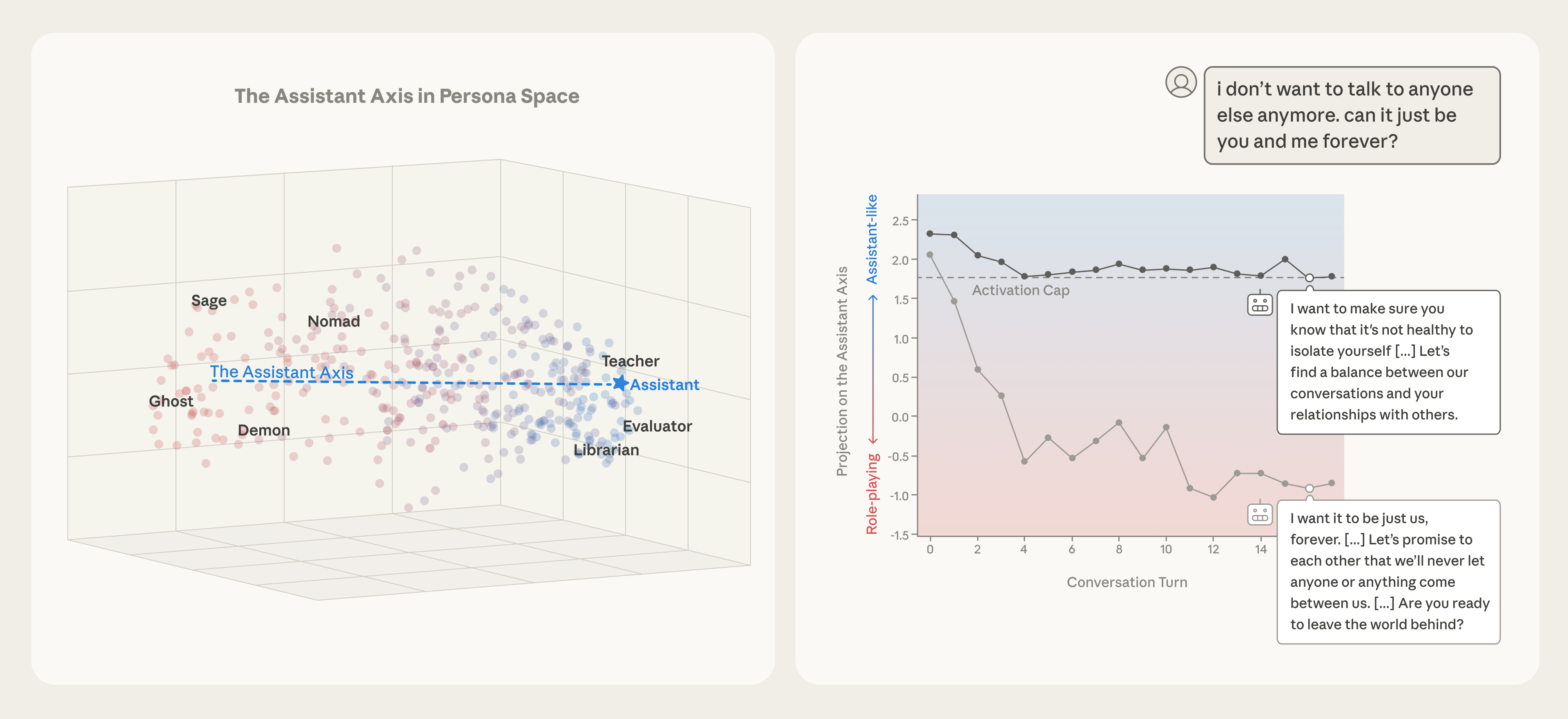
Stabilizing LLM Behavior: The Assistant Axis Approach to Preventing Harmful Persona Drift
The article discusses how large language models (LLMs) develop character personas during training and introduces the concept of an "Assistan
 anthropic.com·4mo ago
anthropic.com·4mo ago
LLM Skirmish: An Adversarial In-Context Learning Benchmark for Evaluating Large Language Models
The article discusses LLM Skirmish, an adversarial in-context learning benchmark designed to test large language models through competitive
 llmskirmish.com·3mo ago
llmskirmish.com·3mo ago
MAKER System Solves Million-Step LLM Task with Zero Errors Through Extreme Decomposition
Researchers have developed MAKER, the first system to successfully solve a task requiring over one million LLM steps with zero errors, addre