LLM Agents Can Autonomously Hack Salesforce Experience Cloud Sites, Research Shows
By
TheHackerNews
A weekday bagel. Dependable, satisfying, no fuss.
Summary
Reco's research demonstrates that AI-powered LLM agents can autonomously hack Salesforce Experience Cloud sites by mapping attack surfaces, identifying vulnerabilities like broken access control and SOQL injection, writing exploits, and extracting sensitive data without human guidance. Real-world testing on organizations such as Aegis Security and Helios confirmed the effectiveness of these autonomous attacks.
Key quotes
· 2 pulledAI-powered agents are now able to autonomously map Salesforce Experience Cloud attack surfaces, identify vulnerabilities, write exploits, and extract sensitive data without human guidance.
Reco's research showed real-world impact on organizations like Aegis Security and Helios, exposing broken access control, SOQL injection, and confidential file access.
You might also wanna read

Security Analysis: AI Agent Frameworks' Code Execution Vulnerabilities and WASM Sandbox Solution
The article discusses security vulnerabilities in popular AI agent frameworks like LangChain, AutoGen, and SWE-Agent that execute LLM-genera
 github.com·4mo ago
github.com·4mo ago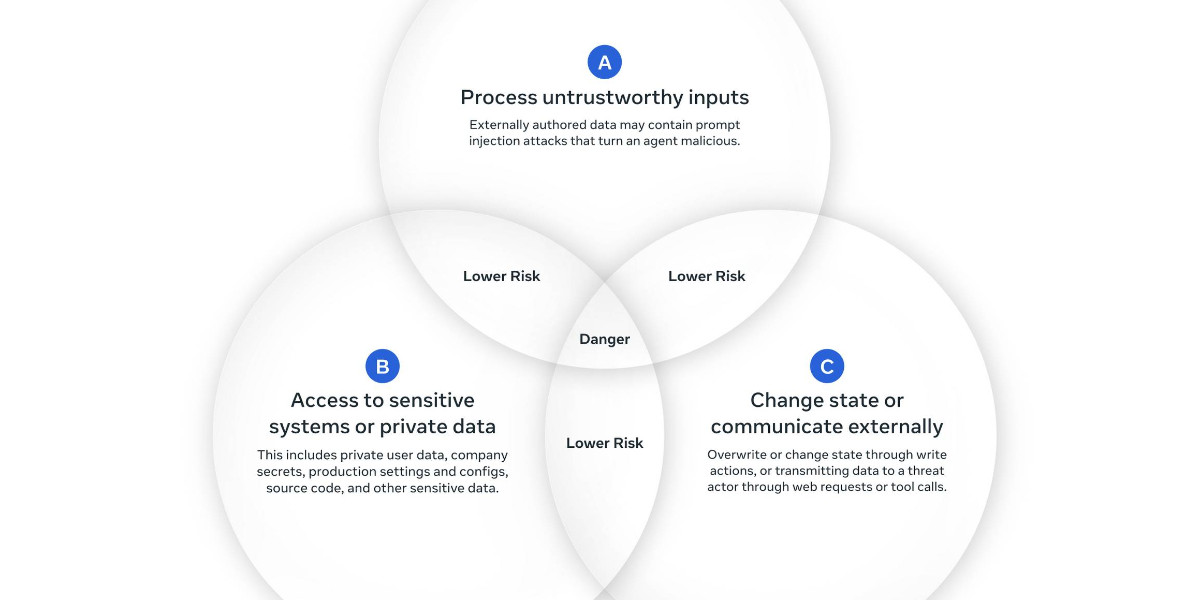
New Research Papers Address LLM Security and Prompt Injection Vulnerabilities
The article discusses two new research papers on LLM security and prompt injection vulnerabilities. The first paper, 'Agents Rule of Two: A

Research Shows LLMs Vulnerable to "Grooming" Attacks That Exploit Poor Reasoning to Spread Falsehoods
Research reveals that generative AI chatbots lack the reasoning capabilities needed to counter "LLM grooming" — the mass-production and dupl
 americansunlight.substack.com·11mo ago
americansunlight.substack.com·11mo ago
Where to Run the LLM Agent Harness: Sandbox vs. Local Architecture Tradeoffs
This article explores the architectural decision of where to run an LLM agent harness — the core loop that drives an agent by sending prompt

Benchmarking Frontier LLMs on Real-World CVE Patching: Mixed Results and Methodological Challenges
A comprehensive benchmark evaluation of five frontier large language models (LLMs) testing their ability to fix real-world security vulnerab
LLMHub Launches Computer Using Agents: Autonomous AI Workforce Operating on Isolated Computers
LLMHub has launched 'Computer Using Agents,' an AI system that operates on isolated computers to perform tasks autonomously like human emplo
 Product Hunt·8mo ago
Product Hunt·8mo ago