GLM-5.2 (max) AI Model: Intelligence, Performance, and Pricing Analysis
By
theanonymousone
If you only eat one bagel today, this is the bagel.
Summary
Analysis of Z AI's GLM-5.2 (max) model, comparing its intelligence, performance (tokens per second, time to first token), pricing, and context window against other AI models. The article uses the Artificial Analysis Intelligence Index v4.1, which incorporates 9 evaluations including GDPval-AA v2, τ³-Banking, Terminal-Bench v2.1, SciCode, Humanity's Last Exam, GPQA Diamond, CritPt, AA-Omniscience, and AA-LCR. The analysis covers quality benchmarks, price-performance ratios, and speed metrics to position GLM-5.2 (max) within the competitive AI landscape.
Key quotes
· 3 pulledArtificial Analysis Intelligence Index v4.1 incorporates 9 evaluations: GDPval-AA v2, τ³-Banking, Terminal-Bench v2.1, SciCode, Humanity's Last Exam, GPQA Diamond, CritPt, AA-Omniscience, AA-LCR
Reasoning models are indicated by a lightbulb icon
Analysis of Z AI's GLM-5.2 (max) and comparison to other AI models across key metrics including quality, price, performance (tokens per second & time to first token), context window & more
You might also wanna read

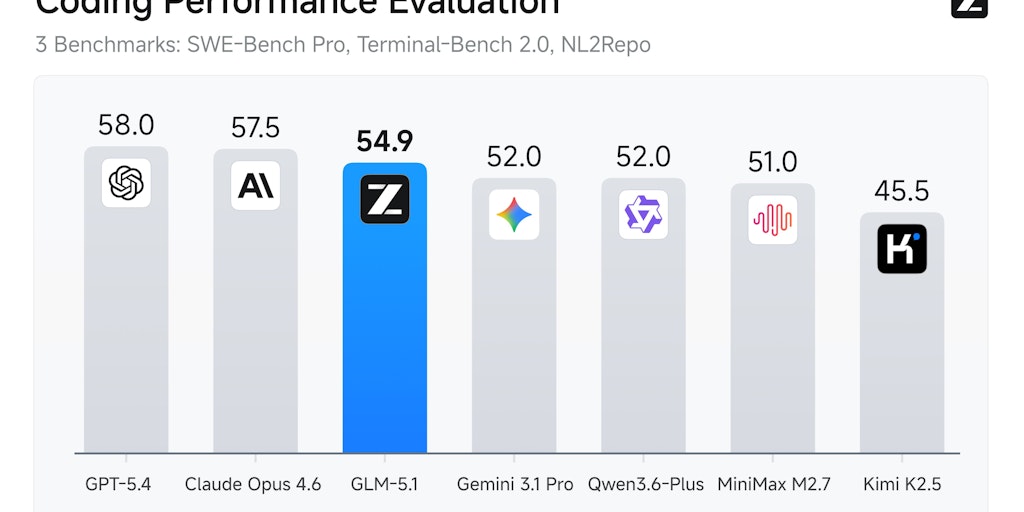
Z.ai Launches GLM-5.1 AI Model for Complex Agentic Coding Tasks
Z.ai has launched GLM-5.1, a next-generation AI model designed for complex agentic coding tasks. The model excels at long-horizon coding wor
 Product Hunt·3mo ago
Product Hunt·3mo ago
Zhipu AI Open-Sources GLM-5.2 With 1 Million Token Context in Response to US Export Restrictions
Zhipu AI has open-sourced its GLM-5.2 model under the MIT license, featuring a 1 million token context window. The release is positioned as
 pandaily.com·2d ago
pandaily.com·2d ago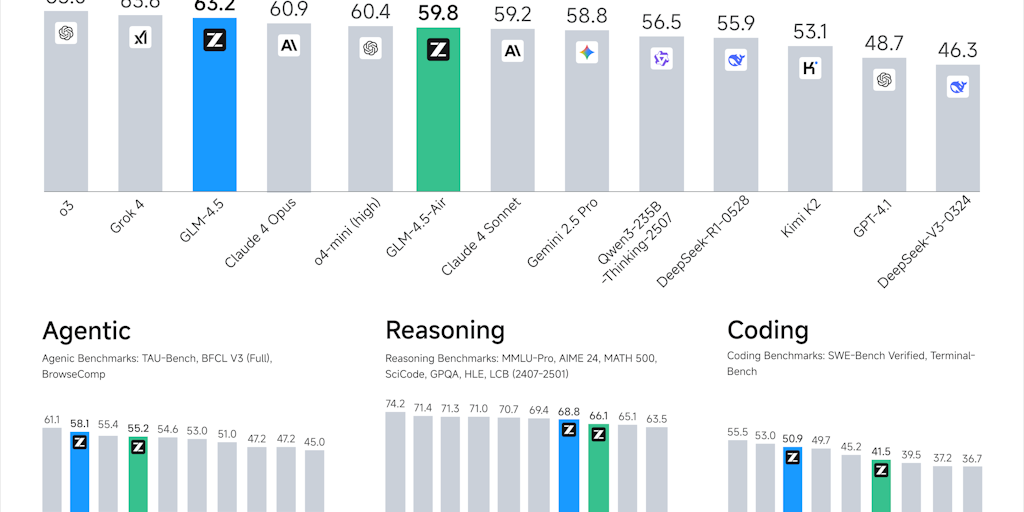
Z.ai Launches Free Playground for MIT-Licensed GLM Models
The article introduces the Z.ai platform, an official playground for high-performance GLM models (Base, Reasoning, Rumination) under an MIT
 Product Hunt·10mo ago
Product Hunt·10mo ago
Measuring the AI Economy: US AI Output Estimates Show 2,000% Annual Quality-Adjusted Growth
This paper (Working Papers 26-9) constructs a macroeconomic estimate of total AI production for the United States by combining inference and
 d.repec.org·12d ago
d.repec.org·12d ago
Alibaba's Qwen3.7-Max ranks 4th globally in coding benchmark, beating OpenAI and Google models
Alibaba's latest AI model, Qwen3.7-Max, has secured the fourth spot globally on the Code Arena coding leaderboard with a score of 1,541, out
 scmp.com·20d ago
scmp.com·20d ago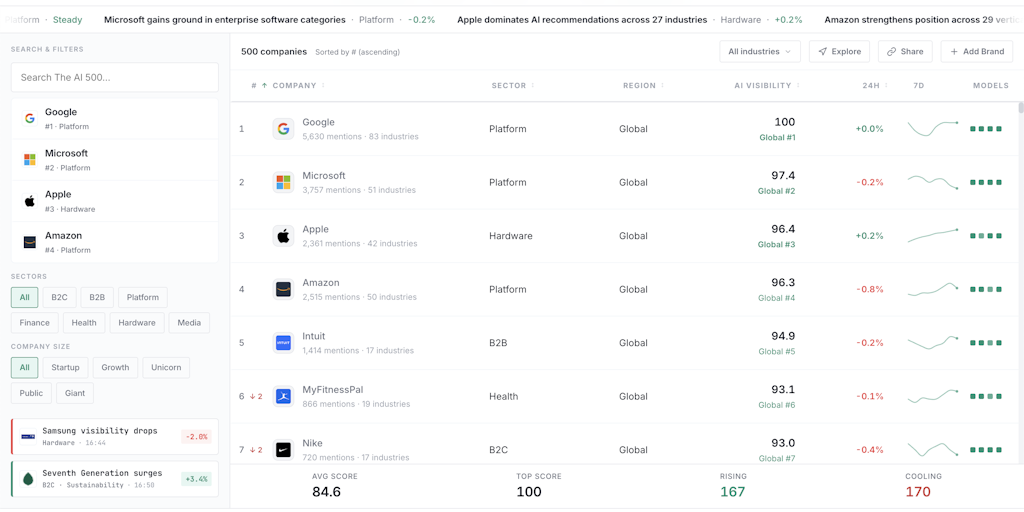
AI 500: Public Benchmark Tracking Brand Visibility Across Major AI Models
The article introduces the AI 500, a public benchmark tracking AI brand visibility across major AI models (ChatGPT, Claude, Gemini, Perplexi
Product Hunt·6mo ago