Exa's exa-d: A Data Framework for Processing Web-Scale Information
By
willbryk
Fresh out the oven, still warm. Top of the tray.
Summary
Exa's exa-d is a custom-built data framework designed to process web-scale data for search applications. The framework was created after evaluating traditional data management stacks and optimizing for specific priorities including typed columns, declarative dependencies, and efficient data processing. The article explains how Exa stores and retrieves web information in a database, detailing their approach to handling large-scale data transformation and enabling team collaboration on search signal development.
Key quotes
· 3 pulledAt Exa, many team members need to simultaneously iterate on new search signals derived from existing data. If each team member wrote bespoke scripts for calculating and updating different columns, this would not only lead to excessive code duplication, but also hamper iteration speed
Before building exa-d, we evaluated traditional data management stacks: data warehouses, SQL transformation layers, and orchestrators before ultimately deciding to build our own data framework optimized around a specific set of priorities
How do you store and retrieve information from the web in a database? A deep dive into Exa's inhouse data processing framework
You might also wanna read


Optimizing .NET APIs for High Throughput: Techniques for 1M Requests Per Minute
Article discusses techniques for designing high-throughput .NET APIs capable of handling 1M requests per minute. It covers horizontal scalin
 blog.elmah.io·14h ago
blog.elmah.io·14h ago
Kore: A New High-Performance Columnar File Format for Big Data Analytics
Kore is a new high-performance binary file format for analytical workloads, claiming superior compression (38% vs 63% for Parquet), 131x que
 github.com·1d ago
github.com·1d ago
SQLite as a Viable Alternative for Durable Workflow Execution
The article argues that SQLite can replace complex orchestration systems for durable workflow execution in many cases. It builds on DBOS's a

JWT vs Opaque Tokens: A Technical Comparison for API Security Architecture
This article compares JWT (JSON Web Tokens) and opaque tokens for API security, clarifying the common confusion between bearer tokens and JW
 nordicapis.com·2d ago
nordicapis.com·2d ago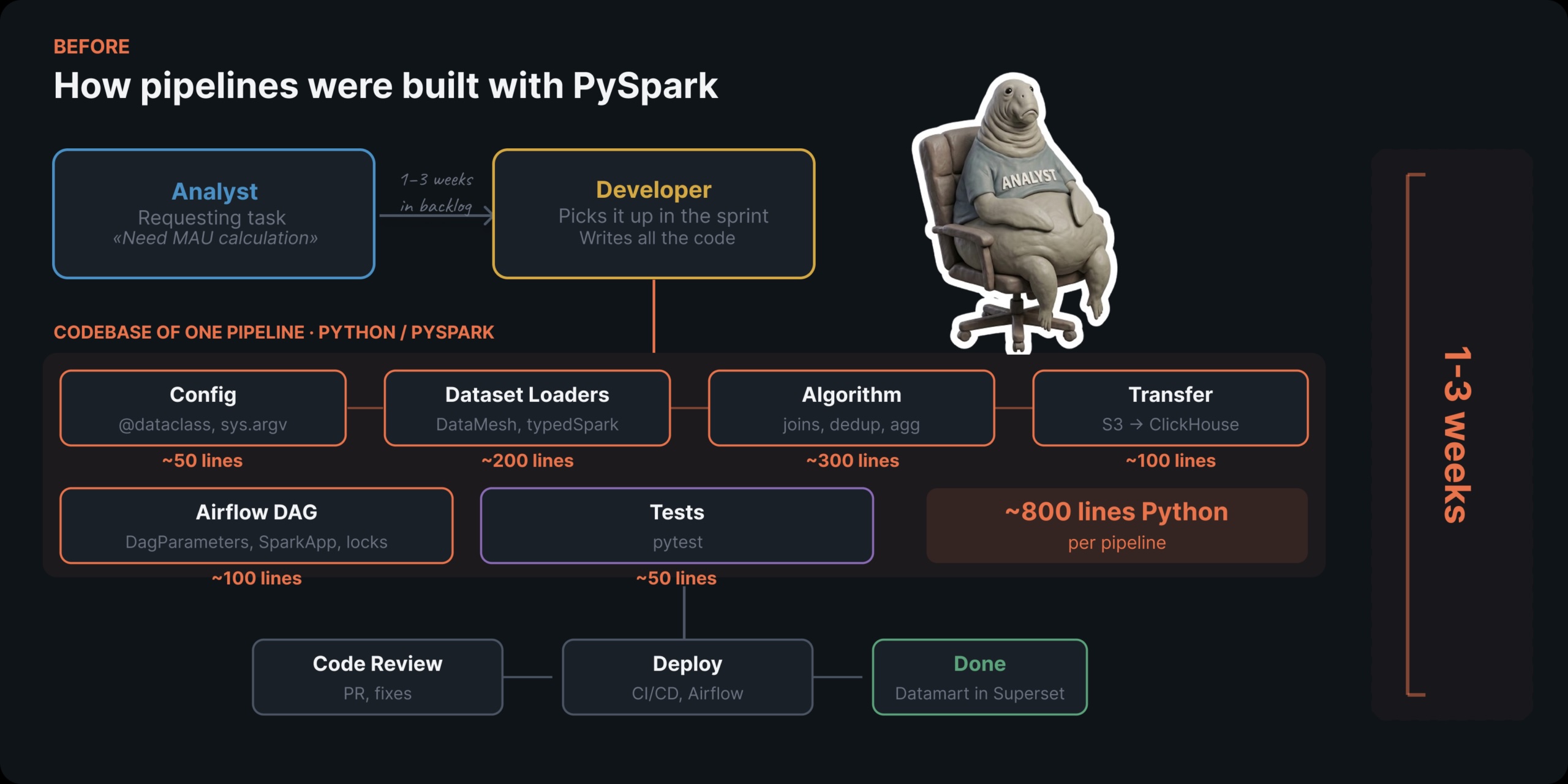
How Mindbox replaced PySpark with YAML-based pipelines using dlt, dbt, and Trino
Data engineer Kiril Kazlou describes how Mindbox replaced PySpark-based data pipelines with a stack using dlt, dbt, and Trino, configured th
 towardsdatascience.com·3d ago
towardsdatascience.com·3d ago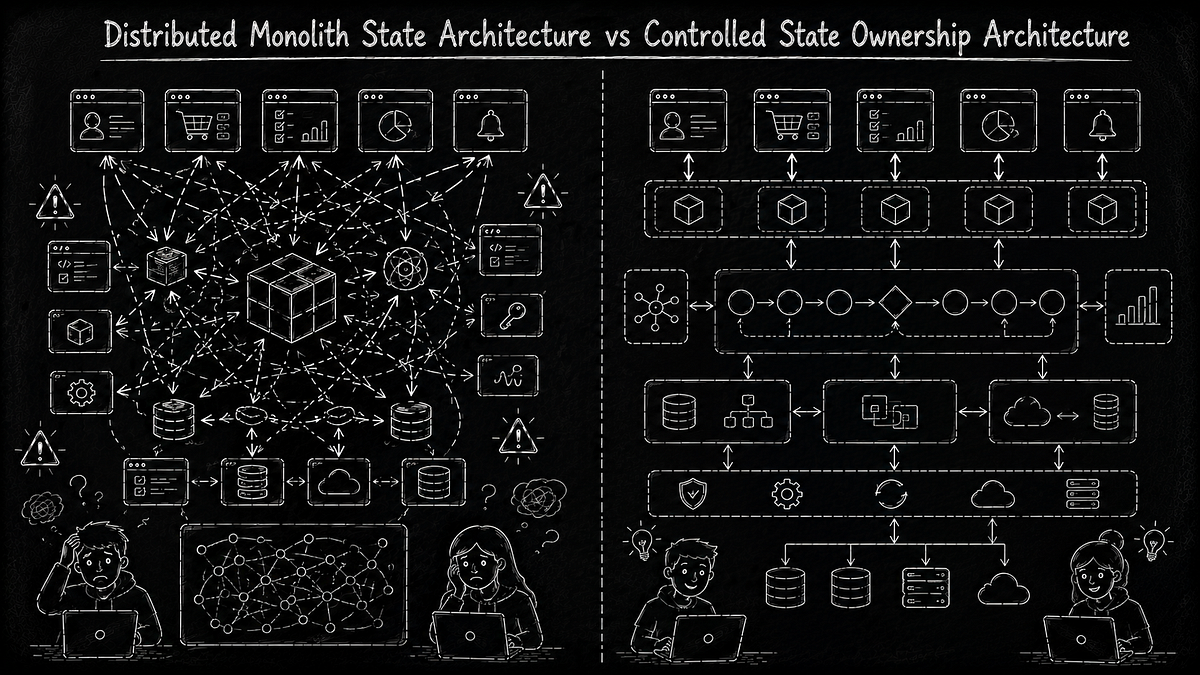
How Frontend State Management Becomes a Distributed Monolith as Apps Scale
This article discusses how frontend state management in growing applications can evolve into a "distributed monolith" — where state becomes
 medium.com·3d ago
medium.com·3d ago