DuckDB Internals: Columnar Storage, SQL Optimization, and Performance Architecture (Part 1)
By
Kyle Cheung
Summary
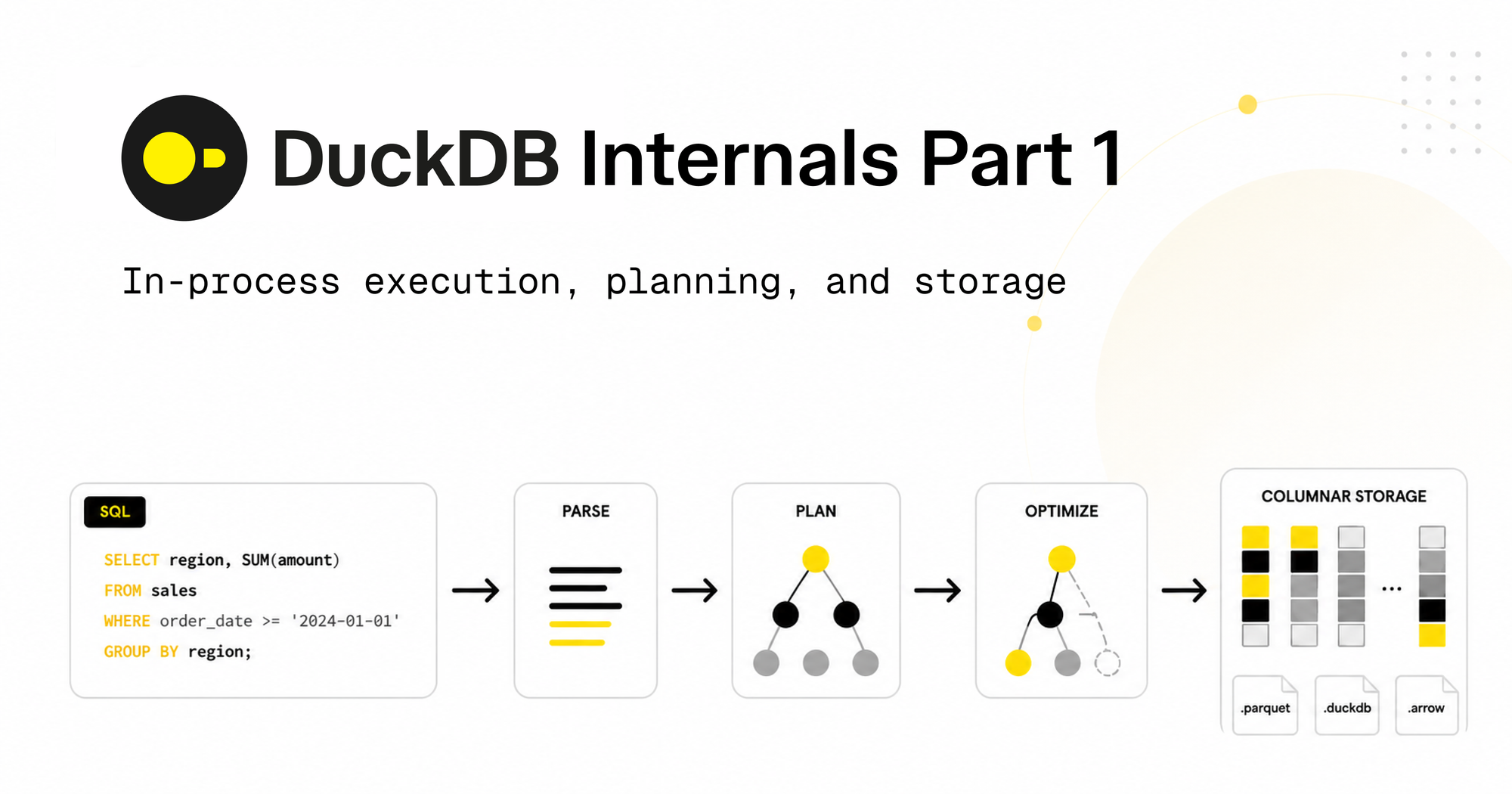
This article explores the internal architecture of DuckDB, explaining why it achieves high performance. It covers how DuckDB eliminates serialization overhead, parses and optimizes SQL queries, and stores data in columnar row groups with zone maps. The piece traces DuckDB's evolution from a 2019 research project at CWI Amsterdam to widespread adoption in notebooks, ETL pipelines, dashboards, and embedded analytics, with companies like MotherDuck, Hex, Omni, and Fivetran building products around it.
Source
 Hacker NewsDuckDB Internals: Columnar Storage, SQL Optimization, and Performance Architecture (Part 1)greybeam.ai
Hacker NewsDuckDB Internals: Columnar Storage, SQL Optimization, and Performance Architecture (Part 1)greybeam.aiKey quotes
· 3 pulledDuckDB has gone from a research project at CWI Amsterdam in 2019 to one of the most widely adopted databases of the past decade.
The list of places it shows up is long: notebooks, ETL pipelines, dashboards, CI test runners, embedded analytics inside SaaS products, even an iPhone running TPC-H at scale factor 100.
Companies have started building real products around it.
You might also wanna read

Summer: First End-to-End Data Stack Powered by DuckDB Launches on Product Hunt
Summer is a new data stack platform that is the first end-to-end solution powered by DuckDB, an open-source analytical database. The article
 Product Hunt·1y ago
Product Hunt·1y ago
Obsidian Adds DuckDB SQL Support, Turning Vaults Into AI-Readable Knowledge Bases
Obsidian's "file over app" design philosophy—using plain markdown files stored locally—makes it an ideal platform for AI agents. The article

MotherDuck's AI lead explains how the startup commercializes DuckDB without forking the open-source database
MotherDuck's AI lead Till Döhmen discusses how the startup commercializes the open-source DuckDB analytical database without forking it. At
 bit.ly·20d ago
bit.ly·20d agoMotherDuck's AI lead explains how the startup commercializes DuckDB without forking the open-source database
MotherDuck's AI lead Till Döhmen discusses how the startup commercializes the open-source DuckDB analytical database without forking it. At
bit.ly·20d ago