DeepSWE: A New Long-Horizon Benchmark for Evaluating Frontier Coding Agents on Complex Engineering Tasks
By
ammar_x
Front-window bakery material. Catches the eye, delivers the goods.
Summary
DeepSWE is a new long-horizon software engineering benchmark designed to evaluate frontier coding agents on original, complex engineering tasks. It addresses shortcomings in existing benchmarks like SWE-bench Pro, which averages only 120 lines of code per task and suffers from verifier misgrading (8% false positives, 24% false negatives). The benchmark also tackles growing concerns about benchmark contamination in frontier AI labs.
Key quotes
· 5 pulledDeepSWE is a long-horizon software engineering benchmark that delivers four major advances over today's public benchmarks
Existing benchmarks fall short on several of these axes
SWE-bench Pro, the leading agentic coding benchmark, has tasks averaging just 120 lines of code to solve
our audit found its verifier misgrades agent outputs at rates of 8% false positives and 24% false negatives
Frontier labs are also raising growing concerns about benchmark contamination
You might also wanna read


Datacurve's DeepSWE Benchmark Shows GPT-5.5 Leading AI Coding Models with 70% Pass Rate
A new benchmark called DeepSWE, released by startup Datacurve, reveals significant performance differences among AI coding models that were
 share.transistor.fm·4d ago
share.transistor.fm·4d ago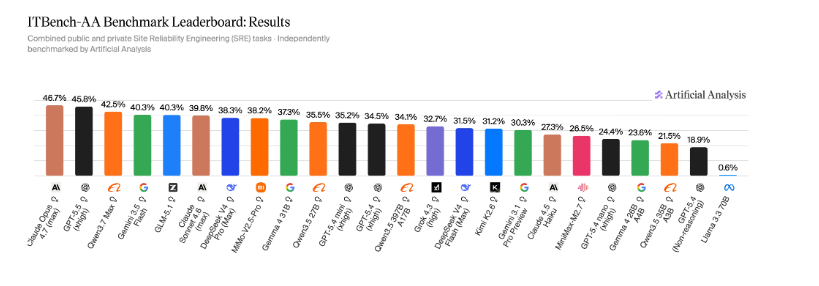
ITBench-AA Benchmark Launched: Frontier AI Models Score Below 50% on Enterprise IT Tasks
Artificial Analysis and IBM Software Innovation Lab have launched ITBench-AA, a new benchmark series evaluating AI models on agentic enterpr