CompileBench: Testing AI Models on Real-World Software Engineering Challenges
By
jakozaur
Front-window bakery material. Catches the eye, delivers the goods.
Summary
CompileBench is a new benchmark that tests 19 state-of-the-art large language models (LLMs) on their ability to handle real-world software engineering challenges, including compiling 22-year-old legacy code, dependency management, and cross-compilation tasks. The benchmark uses unmodified source code from open-source projects like curl to evaluate how well AI models can tackle the messy realities of software development beyond simple code generation.
Key quotes
· 4 pulledWe tested 19 state-of-the-art LLMs on 15 real-world tasks using the unmodified source code of open-source projects like curl
But can they tackle the messy reality of software development – dependency hell, legacy toolchains, and cryptic compile errors?
Today, the best LLMs can generate entire applications from scratch and even win prestigious coding competitions (like IOI 2025)
We created CompileBench to find out how AI models handle real-world software engineering challenges
You might also wanna read

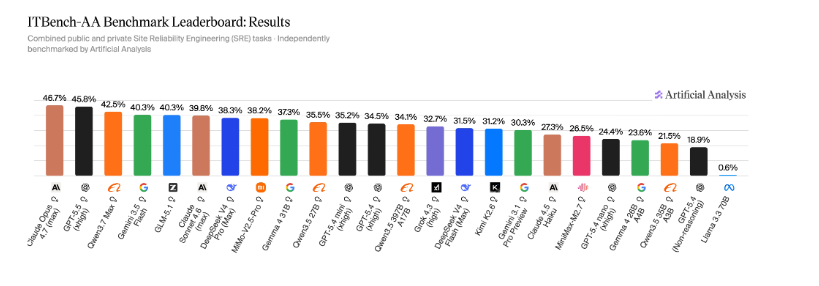
New ITBench-AA Benchmark Reveals AI Models Struggle with Enterprise SRE Tasks
ITBench-AA, a new benchmark developed by Artificial Analysis and IBM Research over six months, reveals that leading AI models like Claude Op
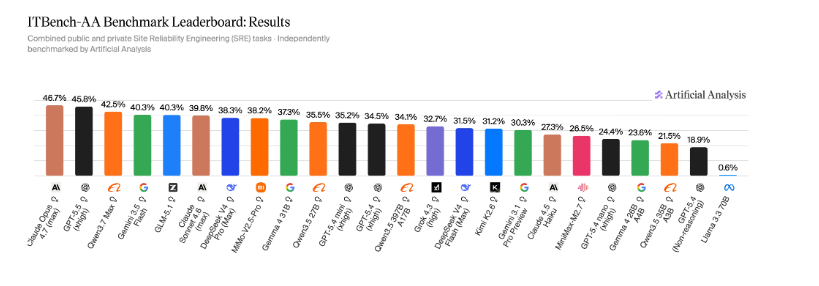
ITBench-AA Benchmark Launched: Frontier AI Models Score Below 50% on Enterprise IT Tasks
Artificial Analysis and IBM Software Innovation Lab have launched ITBench-AA, a new benchmark series evaluating AI models on agentic enterpr

HackerRank Launches Model Kombat: Live Coding Arena Where LLMs Compete on Real Programming Tasks
HackerRank introduces Model Kombat, a live coding arena where large language models (LLMs) compete on real programming tasks. Developers vot
 Product Hunt·8mo ago
Product Hunt·8mo ago
LLM Stats: Platform for Comparing AI Language Models by Benchmarks, Cost, and Capabilities
LLM Stats is a platform that allows users to compare various AI language models (LLMs) across multiple dimensions including performance benc
Product Hunt·7mo ago
Web Bench: A Comprehensive Benchmark for AI Browser Agent Performance
Web Bench is a new benchmark platform designed to evaluate and compare AI browser agents' performance in web navigation tasks. It provides c
Product Hunt·1y ago
Google Labs Launches Stax: AI Evaluation Tool for Objective LLM Testing
Google Labs has launched Stax, a new AI evaluation tool designed to help developers move beyond subjective "vibe testing" of large language
Product Hunt·9mo ago