ChunkLLM: A Lightweight Framework for Accelerating Large Language Model Inference
By
PaulHoule
Right out the toaster. Reliable, with some real depth.
Summary
ChunkLLM is a lightweight, pluggable framework designed to accelerate large language model inference by addressing computational inefficiencies in Transformer-based models. The framework introduces two key components: QK Adapter for feature compression and chunk attention acquisition, and Chunk Adapter for detecting chunk boundaries. During training, only these adapters are trained while the backbone model remains frozen. The system uses attention distillation to enhance key chunk recall and triggers chunk selection only at detected boundaries during inference. Experimental results show ChunkLLM maintains 98.64% performance on long-context benchmarks with 48.58% key-value cache retention and achieves up to 4.48x speedup compared to vanilla Transformers on 120K long texts.
Key quotes
· 5 pulledTransformer-based large models excel in natural language processing and computer vision, but face severe computational inefficiencies due to the self-attention's quadratic complexity with input tokens.
ChunkLLM not only attains comparable performance on short-text benchmarks but also maintains 98.64% of the performance on long-context benchmarks while preserving a 48.58% key-value cache retention rate.
Particularly, ChunkLLM attains a maximum speedup of 4.48x in comparison to the vanilla Transformer in the processing of 120K long texts.
During the training phase, the parameters of the backbone remain frozen, with only the QK Adapter and Chunk Adapter undergoing training.
The former is attached to each Transformer layer, serving dual purposes of feature compression and chunk attention acquisition.
You might also wanna read


RTP-LLM: Alibaba's High-Performance Inference Engine for Large Language Model Deployment
This paper presents RTP-LLM, a high-performance inference engine developed by Alibaba for industrial-scale deployment of Large Language Mode

PromptEmbedder: A Dual-LLM Framework for Efficient, Architecture-Agnostic Text Embedding
The article presents PromptEmbedder, a novel dual-LLM framework for efficient and transferable text embedding. It addresses the bottleneck o
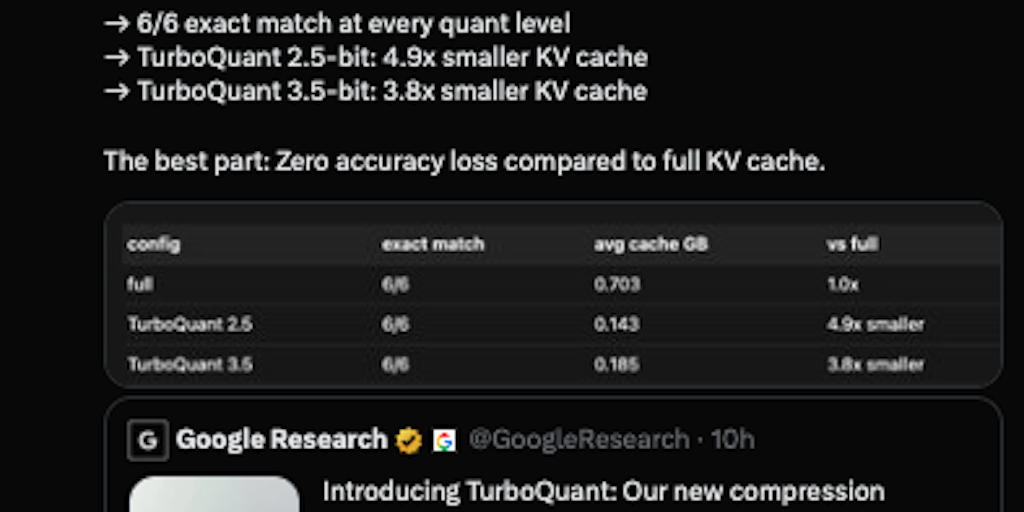
Google Introduces TurboQuant: Advanced LLM Compression Algorithm for Efficient AI Model Deployment
Google has developed TurboQuant, a new LLM compression algorithm that uses advanced theoretically grounded quantization techniques to enable
 Product Hunt·2mo ago
Product Hunt·2mo ago
Parametric Memory Law: A Quantitative Framework for Understanding LoRA Memory Capacity in LLMs
This research paper introduces the Parametric Memory Law, a quantitative framework for understanding how Low-Rank Adaptation (LoRA) enables
Monostate: All-in-One AI Training Platform for Fine-Tuning LLMs
Monostate is an all-in-one AI training platform that enables users to fine-tune large language models (LLMs) with their own data using vario
Product Hunt·2mo ago