vLLM Completes Migration to V1 Engine with DeepSeek Serving at 2.2k Tokens/Second on H200 Hardware
By
robertnishihara
A baker's-dozen of insight crammed into one ring.
Summary
vLLM v0.11.0 marks the complete migration from the V0 engine to the improved V1 engine architecture, representing a significant milestone for the open-source inference serving system. The article highlights vLLM's performance achievements, including DeepSeek-style serving at 2.2k tokens per second on H200 hardware, and its validation through inclusion in SemiAnalysis's InferenceMax benchmarks. The project has substantial community support with nearly 2,000 contributors and is trusted by major companies like Meta, LinkedIn, Red Hat, Mistral, and HuggingFace for production use.
Key quotes
· 4 pulledIn v0.11.0, the last code from vLLM V0 engine was removed, marking the complete migration to the improved V1 engine architecture.
This achievement would not have been possible without vLLM's community of 1,969 contributors, authoring over 950 commits in the past month.
These efforts have been validated by vLLM's inclusion in the SemiAnalysis open source InferenceMax performance benchmarks.
vLLM is proud to be trusted in production by teams at Meta, LinkedIn, Red Hat, Mistral, and HuggingFace.
You might also wanna read


RTP-LLM: Alibaba's High-Performance Inference Engine for Large Language Model Deployment
This paper presents RTP-LLM, a high-performance inference engine developed by Alibaba for industrial-scale deployment of Large Language Mode
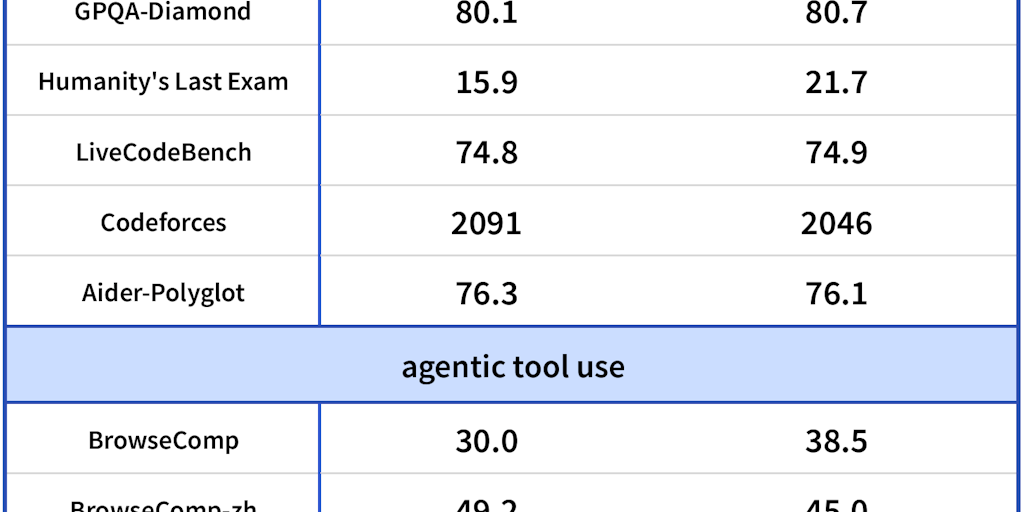
DeepSeek-V3.1-Terminus: Latest Open-Source LLM with Enhanced Stability and Agent Capabilities
DeepSeek-V3.1-Terminus is the latest open-source large language model from DeepSeek, representing the 7th launch in their series. This refin
 Product Hunt·1mo ago
Product Hunt·1mo ago
Ollama v0.7 Launches New Engine for Local Vision Model Execution
Ollama v0.7 introduces a new engine designed for running leading vision models locally, such as Llama 4 and Gemma 3. The update focuses on i
 Product Hunt·10mo ago
Product Hunt·10mo ago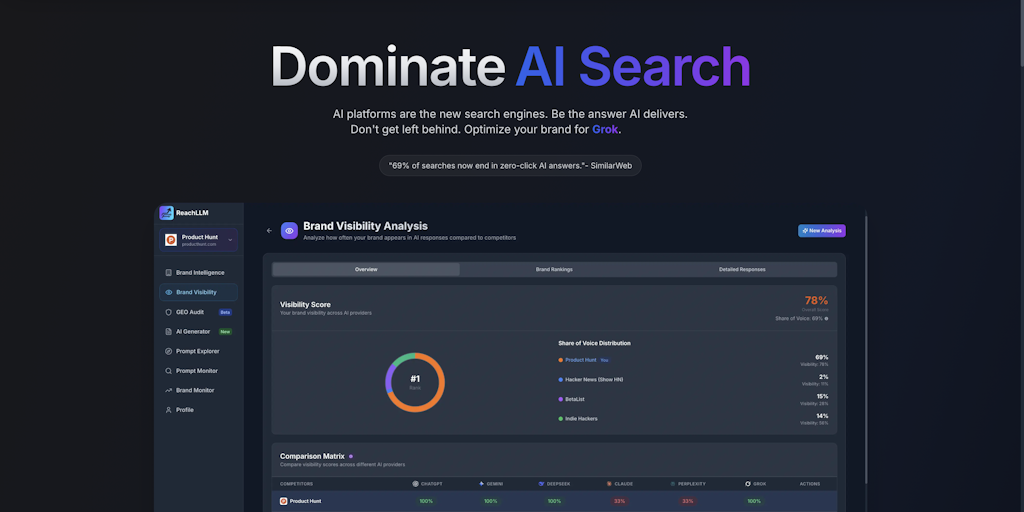
ReachLLM: AI Brand Monitoring and Optimization Platform for Generative Search Engines
ReachLLM is an AI-powered platform that helps businesses monitor how major language models (ChatGPT, Gemini, Claude, Perplexity, Grok, and D
Product Hunt·9mo ago
ReachLLM: AI Search Visibility Tracking and Optimization Tool
ReachLLM is a tool that helps businesses track, analyze, and optimize their visibility across AI search platforms including ChatGPT, Gemini,
Product Hunt·1y ago