The Origin Story of Apache Kafka: Solving LinkedIn's Data Integration Problem
By
enether
The kind of bagel that ruins lesser bagels for you.
Summary
This article explores the original motivation behind creating Apache Kafka at LinkedIn around 2012. It explains that Kafka was built to solve a data integration problem, specifically to handle site activity data (likes, posts, profile views) used for fraud detection, job matching, ML model training, and core website features. The article provides historical context on why LinkedIn needed a new solution and how Kafka's architecture was shaped by these real-world requirements.
Key quotes
· 3 pulledCirca 2012, LinkedIn's original intention with Kafka was to solve a data integration problem.
LinkedIn used site activity data (e.g. someone liked this, someone posted this) for many things - tracking fraud/abuse, matching jobs to users, training ML models, basic features of the website.
We talk all the time about what Kafka is, but not so much about why it is the way it is.
You might also wanna read

Kore: A New High-Performance Columnar File Format for Big Data Analytics
Kore is a new high-performance binary file format for analytical workloads, claiming superior compression (38% vs 63% for Parquet), 131x que
 github.com·1d ago
github.com·1d ago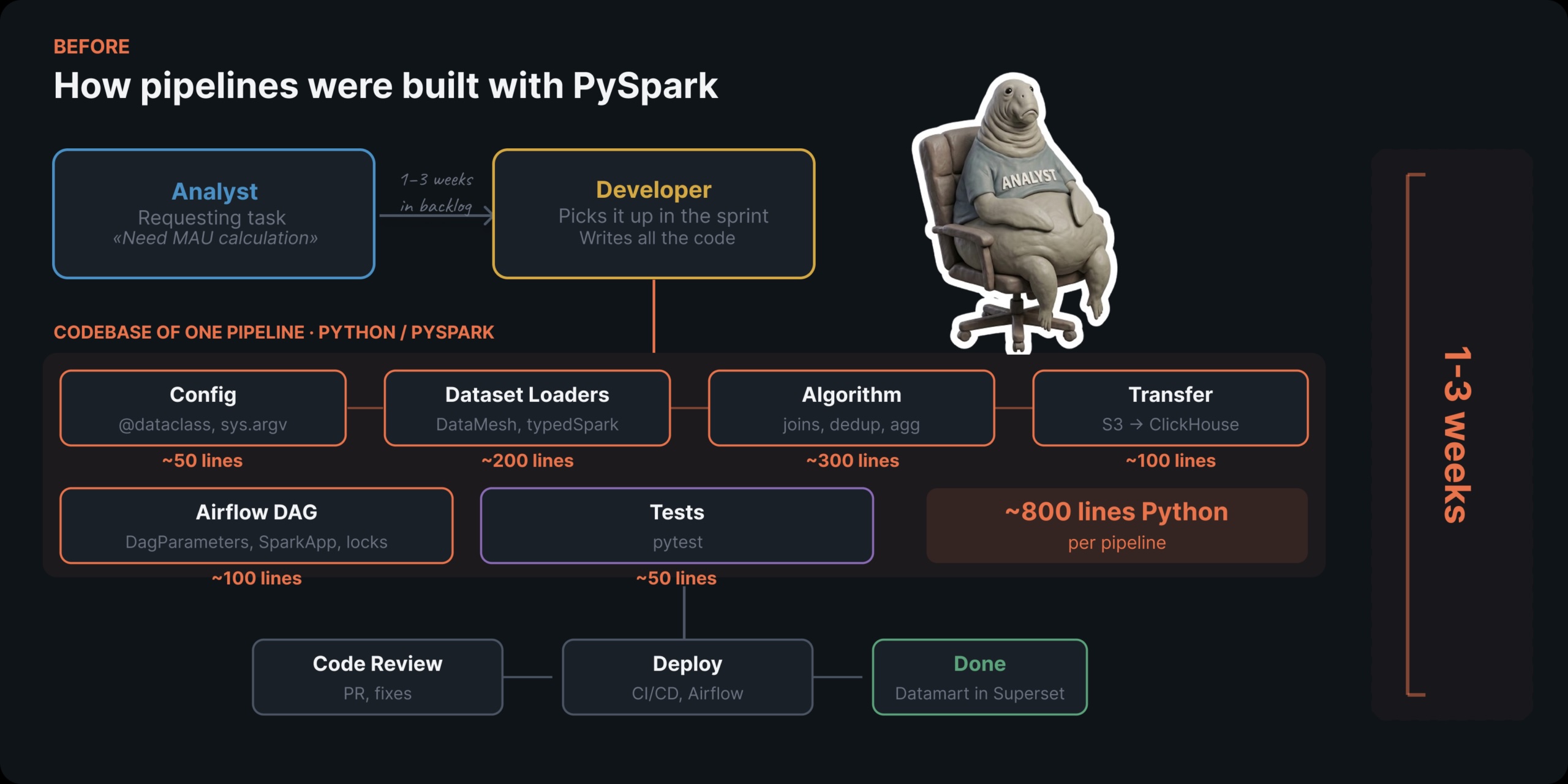
How Mindbox replaced PySpark with YAML-based pipelines using dlt, dbt, and Trino
Data engineer Kiril Kazlou describes how Mindbox replaced PySpark-based data pipelines with a stack using dlt, dbt, and Trino, configured th
 towardsdatascience.com·3d ago
towardsdatascience.com·3d agoSix SQL patterns for detecting transaction fraud in benefit programs
A data professional on a program-integrity team shares six practical SQL patterns for detecting transaction fraud in government benefit prog
ReactOS Celebrates 30 Years of Open-Source Windows Reimplementation
ReactOS, the free and open-source reimplementation of Windows, celebrates its 30th anniversary since the first commit to its source tree. Th
 reactos.org·18d ago
reactos.org·18d ago
PipeDream on the Acorn Archimedes: A Retrospective on a Defiant Productivity Suite
A deep-dive retrospective on PipeDream, a productivity suite for the Acorn Archimedes computer. The article explores how this software rejec
 stonetools.ghost.io·22d ago
stonetools.ghost.io·22d ago
A veteran developer asks: What did VB6 get right that modern .NET developers miss?
The author, a veteran developer who shipped hundreds of VB3-through-VB6 line-of-business systems between 1995 and 2010, poses two open quest
 evilgeniuslabs.ca·1mo ago
evilgeniuslabs.ca·1mo ago