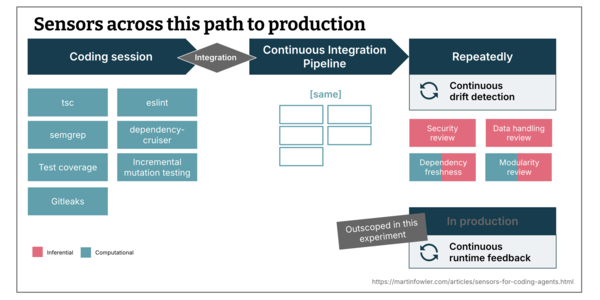
SWE-CI: A Continuous Integration Benchmark for Evaluating LLM Agents' Code Maintenance Capabilities
By
mpweiher
2mo ago· 2 min readenInsight
75/100
Toasty
Bagelometer↗
Toasted to a respectable shade. No regrets, no crumbs left.
Score75TypeanalysisSentimentneutral
Summary
Researchers propose SWE-CI, a new benchmark for evaluating LLM-powered software engineering agents' ability to maintain codebases over time through continuous integration. Unlike static bug-fixing benchmarks, SWE-CI focuses on long-term maintainability by tracking functional correctness changes across development histories averaging 233 days and 71 commits. The benchmark includes 100 real-world repository tasks requiring agents to perform dozens of analysis and coding iterations, shifting evaluation from short-term functional correctness to dynamic, long-term maintainability.
Key quotes
· 5 pulledLarge language model (LLM)-powered agents have demonstrated strong capabilities in automating software engineering tasks such as static bug fixing.
To bridge this gap, we propose SWE-CI, the first repository-level benchmark built upon the Continuous Integration loop, aiming to shift the evaluation paradigm for code generation from static, short-term functional correctness toward dynamic, long-term maintainability.
The key insight is simple: Maintainability can be revealed by tracking how functional correctness changes over time.
SWE-CI requires agents to systematically resolve these tasks through dozens of rounds of analysis and coding iterations.
SWE-CI provides valuable insights into how well agents can sustain code quality throughout long-term evolution.
Large language model (LLM)-powered agents have demonstrated strong capabilities in automating software engineering tasks such as static bug fixing. However, in the real world, the development of mature software is typically predicated on complex requireme