Why Treating LLMs as Black-Box Problem Solvers Fails: Lessons from Processing 100 Compliance PDFs
By
Clara Chong
A baker's-dozen of insight crammed into one ring.
Summary
The article discusses the author's experience transforming 100 messy compliance PDFs into structured JSON rules. It critiques the common approach of using LLMs as brute-force problem solvers, showing how initial promising results (valid JSON output) hid deeper issues like overly broad rules, missed nuances, and inaccuracies. The author advocates for a more structured, deterministic approach with validation loops around LLM agents rather than treating them as giant black-box problem solvers.
Key quotes
· 3 pulledThe brute force approach was obvious: give the agent the source text, explain the task, provide examples, and ask it to generate the rules.
At a glance, the output looked fine. The output JSON was valid and matched what I expected.
But as I was manually sampling the results to check for accuracy, the cracks appeared. Some rules were too broad, others were missed. Some rules failed to preserve the nuances of the original text.
You might also wanna read


Common Anti-Patterns to Avoid When Working with Large Language Models
The article discusses common anti-patterns to avoid when working with Large Language Models (LLMs), based on 15 months of experience. It ide
 instavm.io·6mo ago
instavm.io·6mo ago
Reflections on LLMs and Their Impact on Software Development Practices
The author shares personal reflections on the current state of Large Language Models (LLMs) and AI in software development, questioning whet
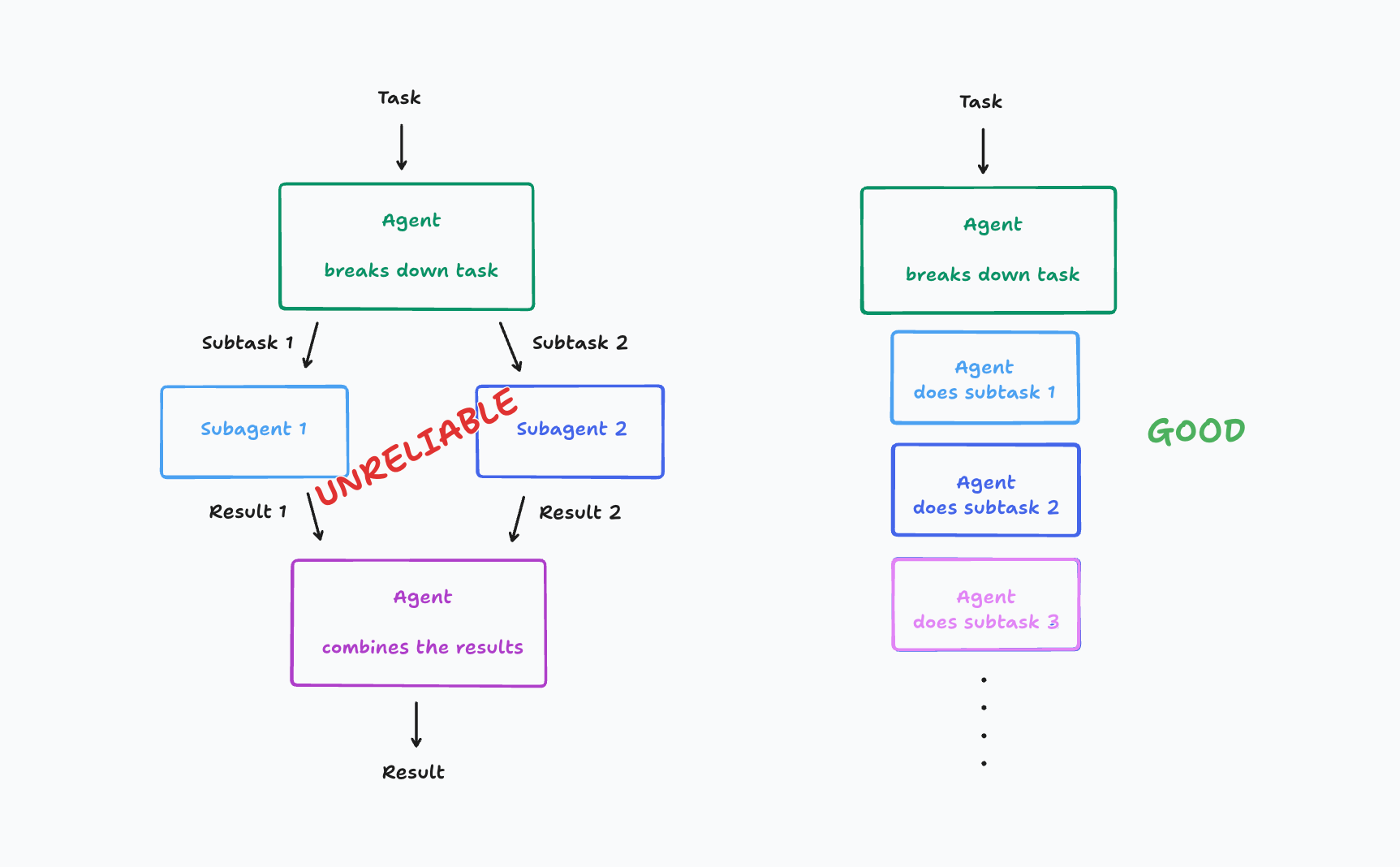
Principles for Effective LLM Agent Development: Avoiding Multi-Agent Pitfalls
The article critiques current LLM agent frameworks and proposes principles for building effective agents based on the author's practical exp
 cognition.ai·9mo ago
cognition.ai·9mo agoWhy LLM Evaluation Methods Fail When Models Enter New Capability Regimes
The article argues that current evaluation methods for LLMs are fundamentally flawed because they assume future models will be incremental i

The Problem with Structured Outputs in LLMs: How Constrained Decoding Creates False Confidence
This article critiques the use of structured outputs and constrained decoding in large language models (LLMs), arguing that while these tech
 boundaryml.com·5mo ago
boundaryml.com·5mo ago
Research Reveals Reasoning LLMs Lack Systematic Problem-Solving Capabilities
This research paper analyzes the reasoning capabilities of Large Language Models (LLMs), arguing that current reasoning LLMs lack systematic