SQLFlow Quickstart Guide: Create a Kafka Stream Processor in 5 Minutes
By
dm03514
Toasted just enough. A reliable bake, gently seasoned.
Summary
This is a technical tutorial/documentation article that provides a quickstart guide for SQLFlow, a stream processing tool. It explains how to set up and run a stream processor that reads data from Kafka and executes SQL queries against the stream, with output written to the console. The article outlines the prerequisites including Docker, cloning the SQLFlow repository, installing Python dependencies, pulling the Docker image, and having Kafka running locally. The goal is to get users started with stream processing in under 5 minutes.
Key quotes
· 5 pulledCreate a stream processor that reads data from Kafka in less than 5 minutes.
Get started by running a stream processor that executes SQL against a kafka stream and writes the output to the console.
What you'll need: Docker, A copy of turbolytics/sql-flow cloned on your local machine, turbolytics/sql-flow Python dependencies installed
cd path/to/turbolytics/sql-flow/github/repo && pip install -r requirements.txt
The turbolytics/sql-flow docker image: docker pull turbolytics/sql-flow:latest
You might also wanna read

Kore: A New High-Performance Columnar File Format for Big Data Analytics
Kore is a new high-performance binary file format for analytical workloads, claiming superior compression (38% vs 63% for Parquet), 131x que
 github.com·1d ago
github.com·1d ago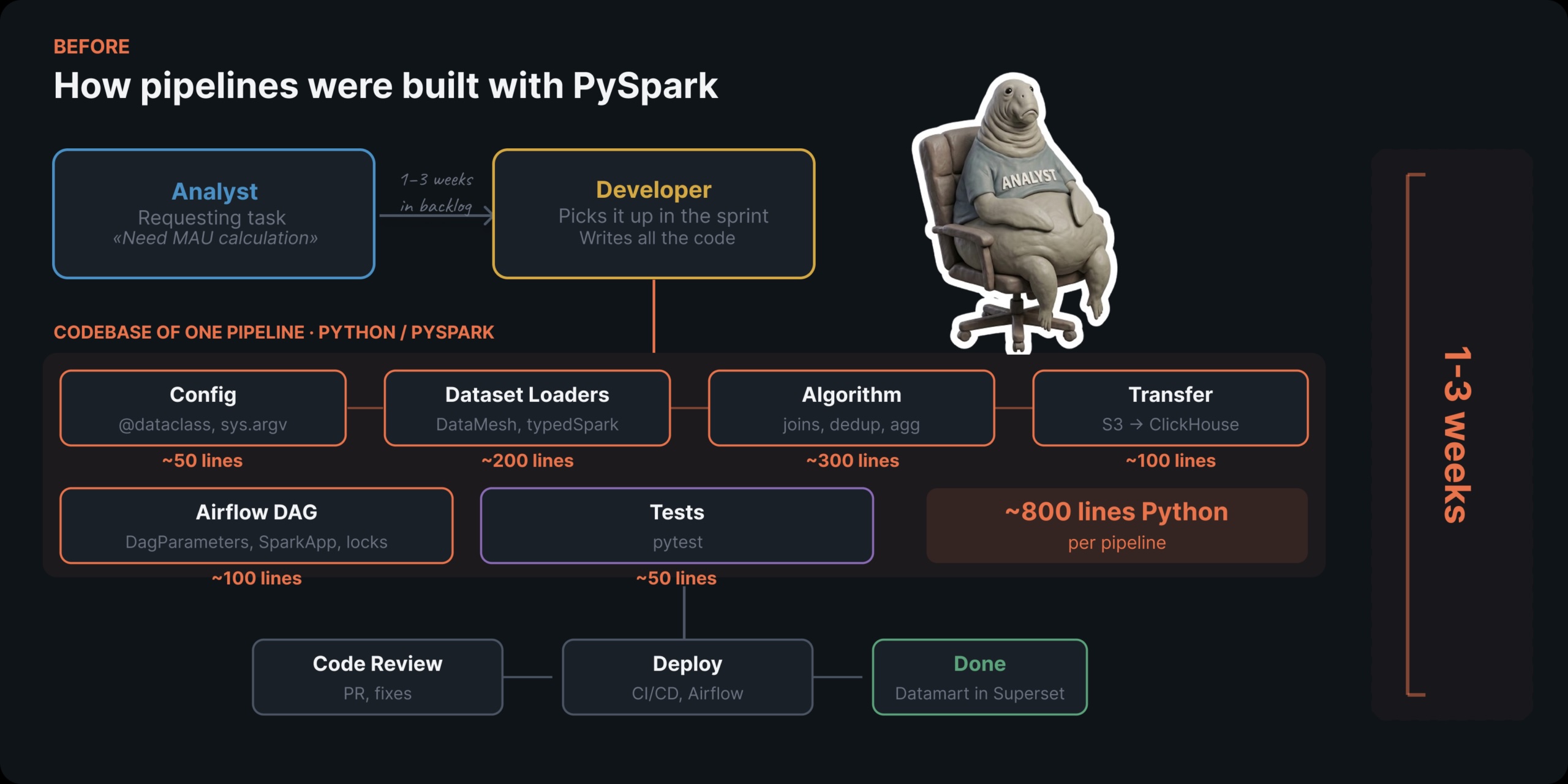
How Mindbox replaced PySpark with YAML-based pipelines using dlt, dbt, and Trino
Data engineer Kiril Kazlou describes how Mindbox replaced PySpark-based data pipelines with a stack using dlt, dbt, and Trino, configured th
 towardsdatascience.com·3d ago
towardsdatascience.com·3d agoSix SQL patterns for detecting transaction fraud in benefit programs
A data professional on a program-integrity team shares six practical SQL patterns for detecting transaction fraud in government benefit prog

Rocky: A Rust-Based Control Plane for Data Warehouse Pipeline Management
Rocky is a Rust-based control plane for data warehouse pipelines that provides branching, replay, column-level lineage, compile-time safety,
github.com·1mo ago
Zibra AI Launches GPU-Native Data Orchestration Platform for Spatial AI Training
Zibra AI introduces a GPU-native data orchestration platform designed to solve I/O bottlenecks in spatial and physical AI training. The plat
 Product Hunt·1mo ago
Product Hunt·1mo ago
Columnar Storage as Database Normalization: Understanding the Relational Foundation
The article explains that columnar storage in databases is essentially a form of normalization within the relational model, not a completely
 buttondown.com·1mo ago
buttondown.com·1mo ago