Spice.ai Launches Spice Cayenne Data Accelerator for High-Scale Data Lake Workloads
By
lukekim
Slow-proofed and worth the wait. Worth its weight in flour.
Summary
Spice.ai introduces Spice Cayenne, a next-generation data accelerator designed for high-scale, low-latency data lake acceleration workloads. It combines the Vortex columnar format with an embedded metadata engine to deliver faster queries and significantly lower memory usage compared to existing data accelerators like DuckDB and SQLite. The article presents this as a technical announcement about a new open-source SQL query engine that enables development teams to federate, accelerate, search, and integrate AI across distributed data sources.
Key quotes
· 3 pulledSpice Cayenne is the next-generation Spice.ai data accelerator built for high-scale and low latency data lake acceleration workloads.
It combines the Vortex columnar format with an embedded metadata engine to deliver faster queries and significantly lower memory usage than existing Spice data accelerators, including DuckDB and SQLite.
Spice.ai is a modern, open-source SQL query engine that enables development teams to federate, accelerate, search, and integrate AI across distributed data sources.
You might also wanna read

Kore: A New High-Performance Columnar File Format for Big Data Analytics
Kore is a new high-performance binary file format for analytical workloads, claiming superior compression (38% vs 63% for Parquet), 131x que
 github.com·1d ago
github.com·1d ago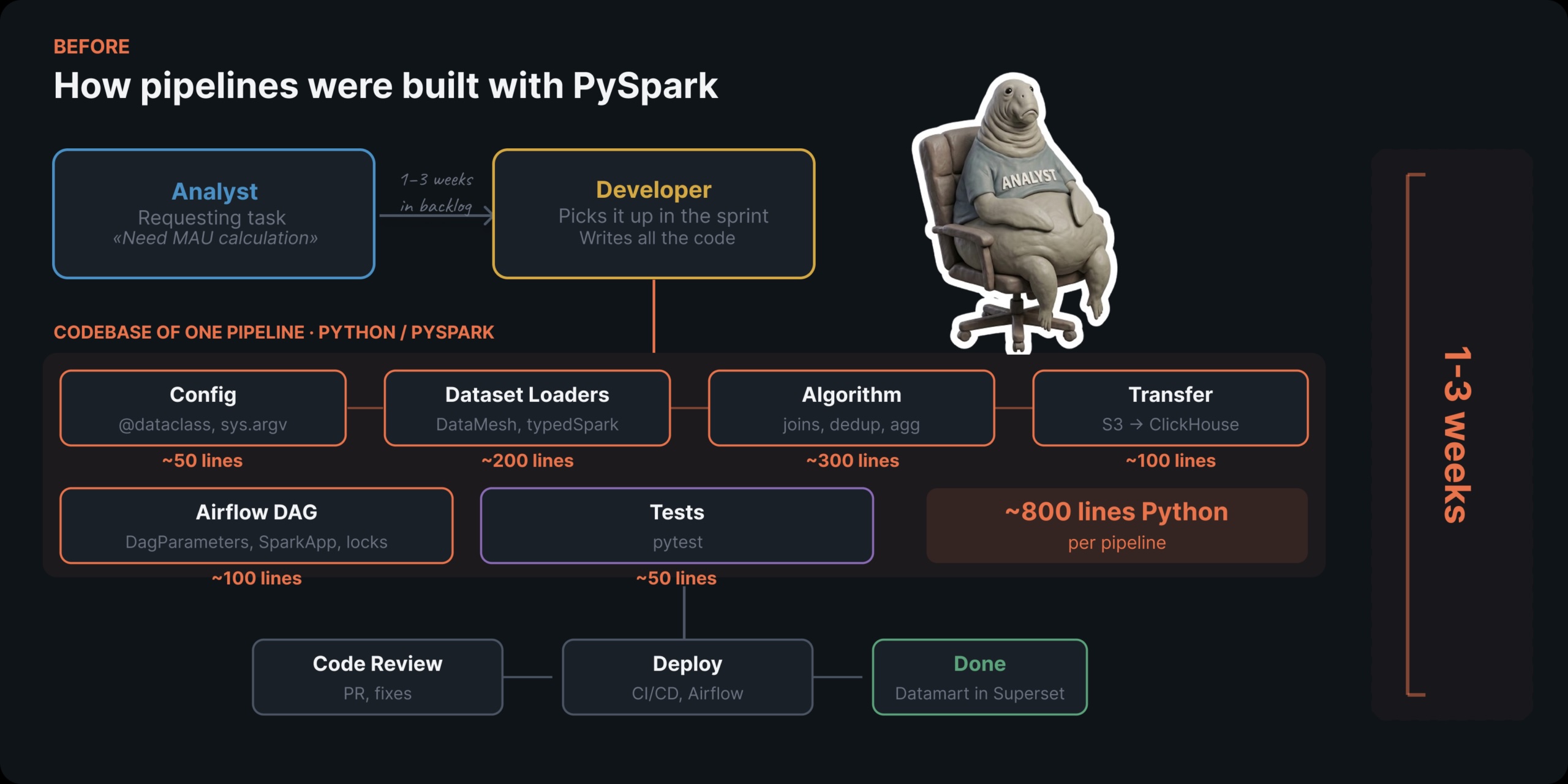
How Mindbox replaced PySpark with YAML-based pipelines using dlt, dbt, and Trino
Data engineer Kiril Kazlou describes how Mindbox replaced PySpark-based data pipelines with a stack using dlt, dbt, and Trino, configured th
 towardsdatascience.com·3d ago
towardsdatascience.com·3d agoSix SQL patterns for detecting transaction fraud in benefit programs
A data professional on a program-integrity team shares six practical SQL patterns for detecting transaction fraud in government benefit prog

Rocky: A Rust-Based Control Plane for Data Warehouse Pipeline Management
Rocky is a Rust-based control plane for data warehouse pipelines that provides branching, replay, column-level lineage, compile-time safety,
github.com·1mo ago
Zibra AI Launches GPU-Native Data Orchestration Platform for Spatial AI Training
Zibra AI introduces a GPU-native data orchestration platform designed to solve I/O bottlenecks in spatial and physical AI training. The plat
 Product Hunt·1mo ago
Product Hunt·1mo ago
Columnar Storage as Database Normalization: Understanding the Relational Foundation
The article explains that columnar storage in databases is essentially a form of normalization within the relational model, not a completely
 buttondown.com·1mo ago
buttondown.com·1mo ago