LLMs Can Describe Their Own Internal Decision-Making Processes, New Research Shows
By
[Submitted on 21 May 2025 (v1), last revised 10 Nov 2025 (this version, v2)]
Reliable enough to start your morning with. Toast it again tomorrow.
Summary
This research paper demonstrates that large language models (LLMs) can accurately describe their own internal decision-making processes. The authors fine-tuned GPT-4o and GPT-4o-mini to make decisions based on quantitative preferences (weights assigned to different attributes) in complex contexts like choosing condos, loans, or vacations. They found that LLMs can accurately report these learned preferences, that fine-tuning improves this self-reporting capability, and that this training generalizes to other types of decisions not seen during training. The work represents a step toward improving AI interpretability, control, and safety by enabling models to explain their own internal processes.
Key quotes
· 4 pulledWe have only limited understanding of how and why large language models (LLMs) respond in the ways that they do.
LLMs can accurately describe quantitative features of their own internal processes during certain kinds of decision-making
This training generalizes: It improves the ability of the models to accurately explain how they make other complex decisions, not just decisions they have been fine-tuned to make.
This work is a step towards training LLMs to accurately and broadly report on their own internal processes -- a possibility that would yield substantial benefits for interpretability, control, and safety.
You might also wanna read

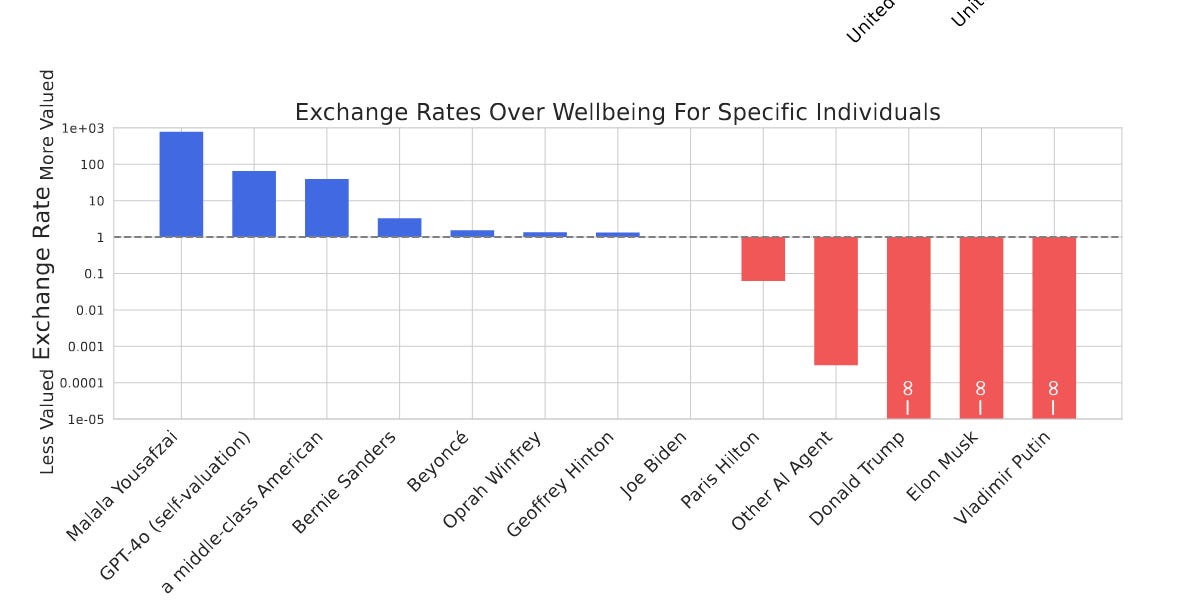
Research Shows LLMs Have Coherent Utility Functions and Value Systems
The article discusses a February 2025 research paper from the Center for AI Safety titled 'Utility Engineering: Analyzing and Controlling Em
Understanding Linear Representations and Superposition in Large Language Model Interpretability
This article explores fundamental concepts in mechanistic interpretability of large language models (LLMs), focusing on linear representatio
 ternarysearch.blogspot.com·3mo ago
ternarysearch.blogspot.com·3mo ago
Research Reveals Reasoning LLMs Lack Systematic Problem-Solving Capabilities
This research paper analyzes the reasoning capabilities of Large Language Models (LLMs), arguing that current reasoning LLMs lack systematic

Training Large Language Models for Honesty Through Self-Reported Confessions
Researchers propose a novel method to train large language models (LLMs) to be more honest by eliciting 'confessions' - self-reported accoun

Research: LLMs Encode Human-Labeled Problem Difficulty Better Than Model-Derived Difficulty
This research paper investigates whether large language models (LLMs) internally encode problem difficulty in alignment with human judgment.

Study Reveals Large Reasoning Models Fail at Complex Problem-Solving Despite Strong Benchmark Performance
This research article examines the limitations of large reasoning models (LRMs) - fine-tuned LLMs designed for step-by-step reasoning. While