Per-Instance TSP Solver Using PPO Achieves 1.66% Gap on d1291 Without Pre-training
By
jivaprime
A bagel that needed a few more minutes. And maybe a fact-check.
Summary
A developer presents a novel approach to solving the Traveling Salesman Problem (TSP) using deep learning without pre-training. Instead of relying on large datasets, the solver uses Proximal Policy Optimization (PPO) to learn from scratch for each specific TSP instance. The core hypothesis is that optimal solutions consist mostly of 'minimum edges' (nearest neighbors) with difficulty arising from a small number of 'exception edges' outside local scope. The approach achieved a 1.66% gap on the TSPLIB d1291 benchmark in about 5.6 hours on a single A100 GPU.
Key quotes
· 5 pulledMost Deep Learning approaches for TSP rely on pre-training with large-scale datasets.
I wanted to see if a solver could learn 'on the fly' for a specific instance without any priors from other problems.
I built a solver using PPO that learns from scratch per instance.
My hypothesis was that while optimal solutions are mostly composed of 'minimum edges' (nearest neighbors), the actual difficulty comes from a small number of 'exception edges' outside of that local scope.
It achieved a 1.66% gap on TSPLIB d1291 in about 5.6 hours on a single A100.
You might also wanna read

Reflections on DwarfStar 4's rapid rise in local AI inference
The author reflects on the unexpected popularity of DwarfStar 4 (DS4), a local AI inference project. They attribute its success to the conve
antirez.com·1d agoReflections on DwarfStar 4's rapid rise in local AI inference
The author reflects on the unexpected popularity of DwarfStar 4 (DS4), a local AI inference project. They attribute its success to the conve
antirez.com·1d ago
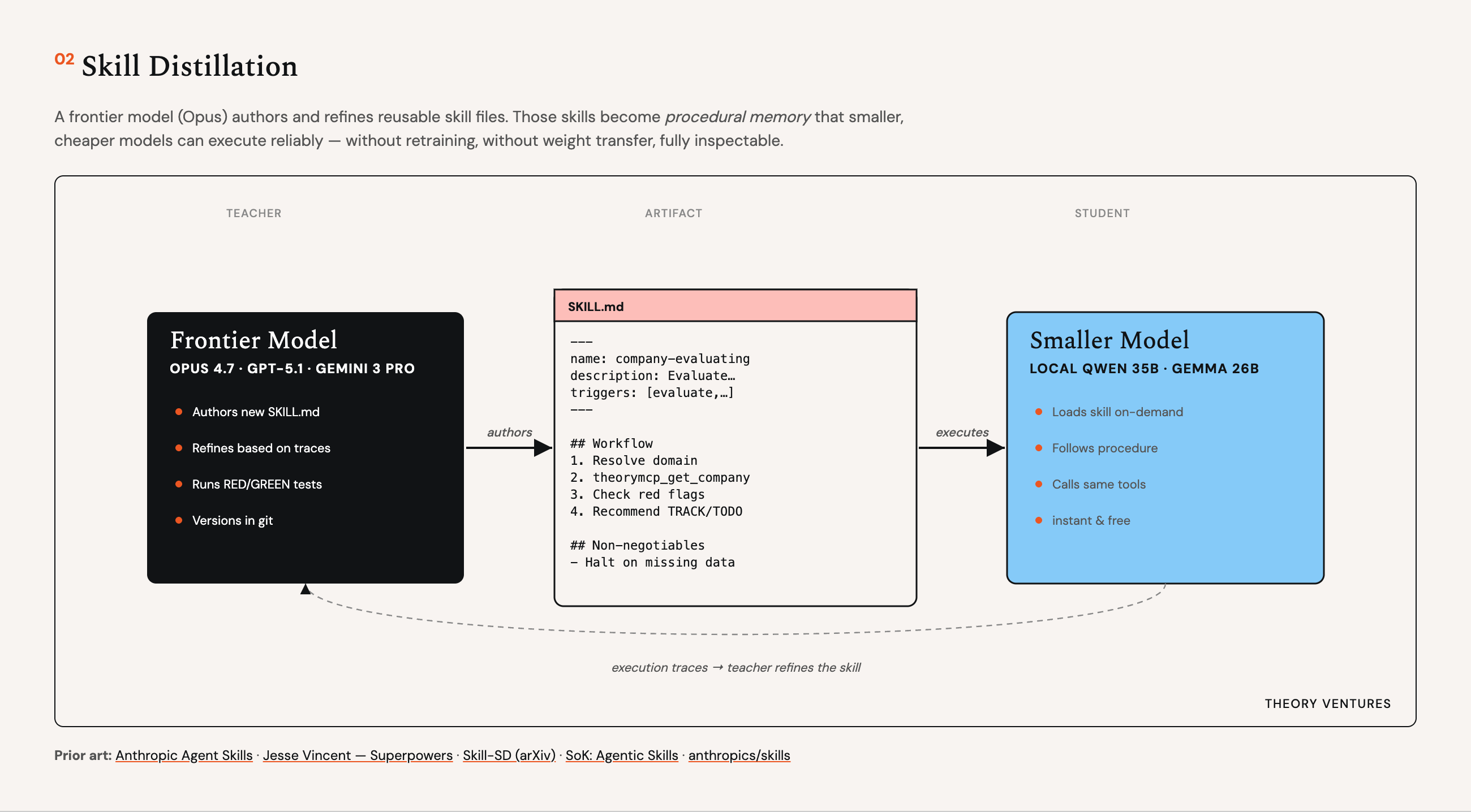
Building a Personal AI Agent with Markdown-Based Skills and Local Models
The article describes a personal AI agent built on Pi that manages the author's inbox, calendar, deal pipeline, blog publishing, and researc
 tomtunguz.com·2d ago
tomtunguz.com·2d ago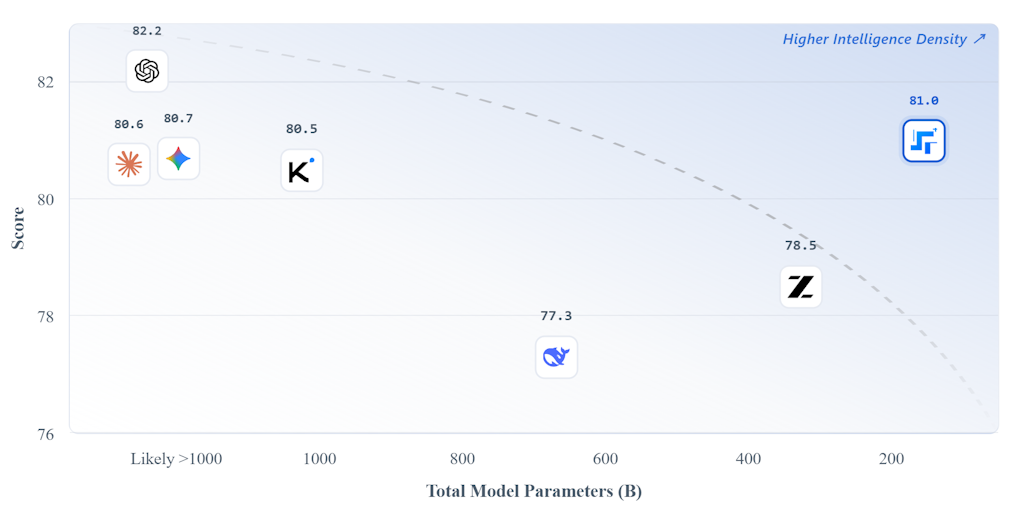
StepFun Releases Step 3.5 Flash: 196B Sparse MoE Model for OpenClaw Agents
StepFun has released Step 3.5 Flash, a 196B sparse Mixture of Experts (MoE) model that activates only 11B parameters per token for high effi
 Product Hunt·2d ago
Product Hunt·2d ago
Anthropic Releases Claude Opus 4.7 AI Model with 1M Context Window and Enhanced Coding Capabilities
Anthropic announces Claude Opus 4.7, their latest AI model featuring a hybrid reasoning architecture with a 1 million token context window.
 anthropic.com·2d ago
anthropic.com·2d agoAnthropic Releases Claude Opus 4.7 AI Model with 1M Context Window and Enhanced Coding Capabilities
Anthropic announces Claude Opus 4.7, their latest AI model featuring a hybrid reasoning architecture with a 1 million token context window.
anthropic.com·2d ago