Pangu Pro MoE: Mixture of Grouped Experts for Efficient Sparsity
By
buyucu
11mo ago· 2 min readNews
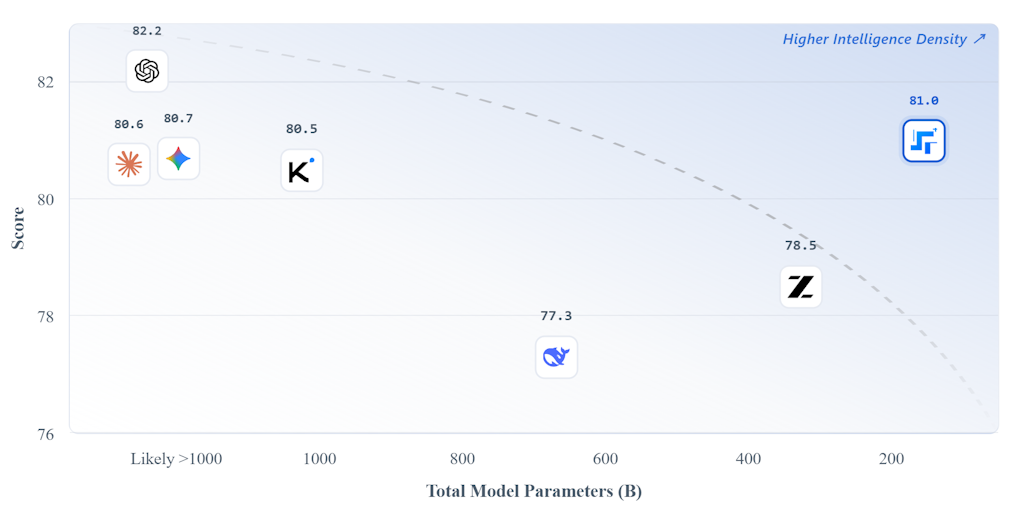
The surgence of Mixture of Experts (MoE) in Large Language Models promises a small price of execution cost for a much larger model parameter count and learning capacity, because only a small fraction of parameters are activated for each input token. Howev