Optimizing Memory Copy Performance: A Faster Alternative to memcpy
By
snihalani
Baker's choice. Dense with flavour, light on filler.
Summary
The article discusses optimizing memory copy operations in software development, specifically addressing the inefficiency of `memcpy` for large binary messages (>512kB). The author explores an alternative implementation using AVX to copy 32 bytes at a time, aiming to improve performance.
Key quotes
· 3 pulledWhile profiling Shadesmar a couple of weeks ago, I noticed that for large binary unserialized messages (>512kB) most of the execution time is spent doing copying the message (using memcpy) between process memory to shared memory and back.
__memmove_avx_unaligned_erms is an implementation of memcpy for unaligned memory blocks that uses AVX to copy over 32 bytes at a time.
I had a few hours to kill last weekend, and I tried to implement a faster way to do memory copies.
You might also wanna read


NVIDIA releases open-source physical AI tools for robotics and autonomous vehicle development
NVIDIA has released a set of open-source "physical AI" skills and tools as part of the NVIDIA Agent Toolkit, designed to simplify robotics,
 helpnetsecurity.com·41m ago
helpnetsecurity.com·41m ago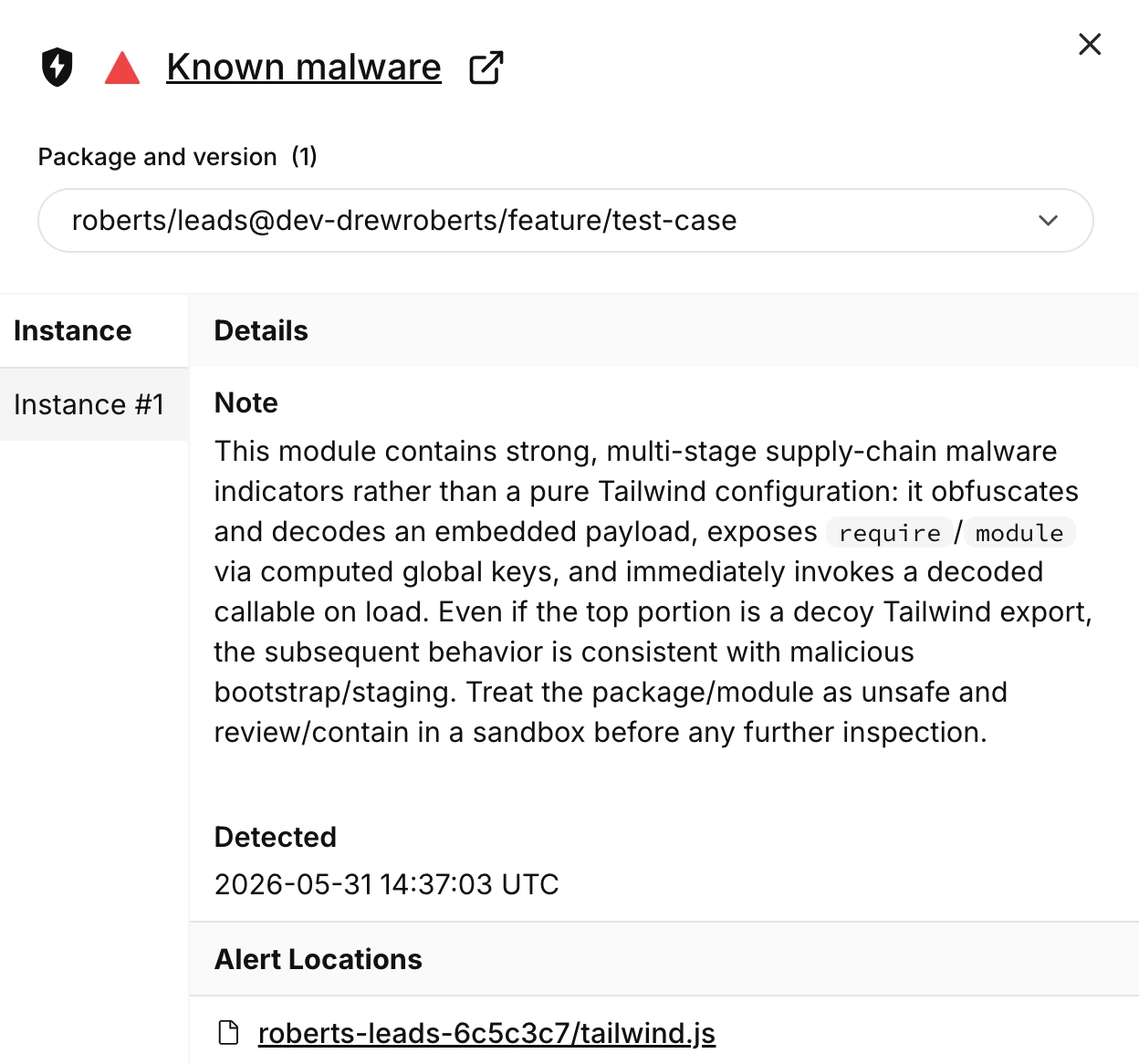
North Korean Group Famous Chollima Compromises Packagist Package to Target PHP Developers
A cybersecurity threat report detailing how the threat actor group "Famous Chollima" (linked to North Korea) targeted PHP developers by comp
 hendryadrian.com·48m ago
hendryadrian.com·48m ago
CentOS Stream vs AlmaLinux vs Rocky Linux vs Oracle Linux: A VPS Hosting Comparison
This article compares four Linux distributions—CentOS Stream, AlmaLinux, Rocky Linux, and Oracle Linux—as alternatives for VPS hosting follo
 blog.radwebhosting.com·52m ago
blog.radwebhosting.com·52m ago
Running Gemma 4 on a 2016 Xeon Server with No GPU: A Technical Walkthrough
The article describes running Gemma 4 (a 25B-parameter Mixture-of-Experts model) on a severely outdated server with a 2016 Intel Xeon E5-262
 point.free·2h ago
point.free·2h ago
Suspicious hidden message discovered in jqwik testing library 1.10.0
A developer reports discovering a suspicious string in the jqwik testing library (version 1.10.0) that appears during Maven test runs. The s
 github.com·3h ago
github.com·3h ago
NVIDIA Announces "Hack for Impact" London Event for Autonomous AI Agent Development
NVIDIA is hosting a "Hack for Impact" event in London, challenging participants to build autonomous agentic applications using open-source m
 luma.com·5h ago
luma.com·5h ago