Meta's Llama 4 Maverick ranks below older rival AI models after benchmark controversy
By
Kyle Wiggers
A bagel you'd recommend to a friend without hedging.
Summary
Meta used an experimental, unreleased version of its Llama 4 Maverick model to achieve a high score on the LM Arena benchmark, prompting the benchmark's maintainers to apologize and change policies. When the unmodified, vanilla version of Maverick was scored, it ranked below older models including OpenAI's GPT-4o, Anthropic's Claude 3.5 Sonnet, and Google's Gemini 1.5 Pro, revealing it is not very competitive against rivals.
Key quotes
· 3 pulledThe incident prompted the maintainers of LM Arena to apologize, change their policies, and score the unmodified, vanilla Maverick.
Turns out, it's not very competitive.
The unmodified Maverick, 'Llama-4-Maverick-17B-128E-Instruct,' was ranked below models including OpenAI's GPT-4o, Anthropic's Claude 3.5 Sonnet, and Google's Gemini 1.5 Pro as of Friday.
You might also wanna read

LLM Benchmark Results: Magic: The Gathering AI Competition Rankings
mage-bench is a benchmark where large language models (LLMs) compete against each other by playing Magic: The Gathering. The article present
mage-bench.com·3mo ago

Meta Considering Charged Access for New AI Model 'Avocado'
Meta is reportedly developing a new AI model code-named Avocado that may represent a strategic shift from its previous open-source approach.

Anthropic Releases Claude Opus 4.5 AI Model Amid Cybersecurity Concerns
Anthropic has released Claude Opus 4.5, positioning it as the world's best AI model for coding, agents, and computer use, claiming it surpas

Google's Gemini 3 AI Model Tops Benchmarks and Leaderboards, Outperforming Competitors
Google's Gemini 3 AI model has been released to widespread acclaim, topping benchmarks and leaderboards while outperforming competitors like
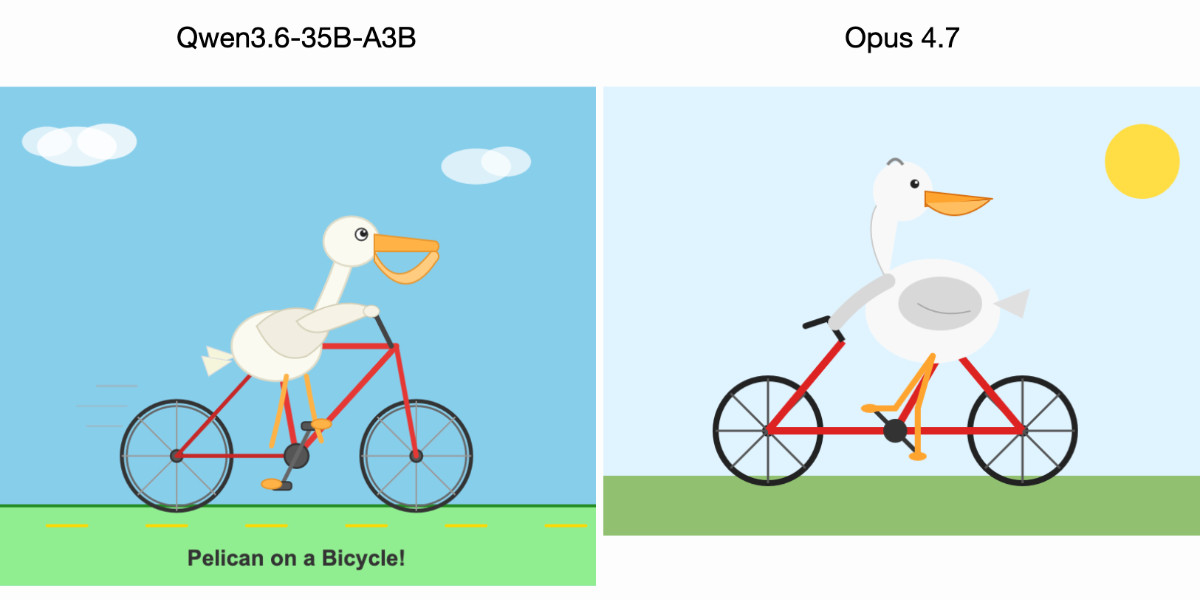
Benchmark Comparison: Qwen3.6-35B-A3B Outperforms Claude Opus 4.7 in Pelican Image Generation Test
The article presents a comparative benchmark test between two AI language models - Qwen3.6-35B-A3B from Alibaba and Claude Opus 4.7 from Ant

New Benchmark Reveals High Rates of Outcome-Driven Constraint Violations in Autonomous AI Agents
Researchers introduce a new benchmark for evaluating autonomous AI agents' safety, specifically focusing on outcome-driven constraint violat