Mesh-LLM: Distributed LLM Inference System Using llama.cpp Across Multiple Machines
By
i386
Pure flour-power. Hearty enough to carry you through lunch.
Summary
Mesh-LLM is a reference implementation that enables distributed inference of large language models across multiple machines by compiling llama.cpp for distributed execution. The system allows pooling spare GPU capacity to run LLMs at larger scale, automatically distributing models that don't fit on a single machine using pipeline parallelism for dense models and expert sharding for MoE models with zero cross-node inference traffic. It features a mesh network architecture where agents can gossip and share information without a central server, and includes installation instructions for macOS and Linux with requirements for building from source.
Key quotes
· 5 pulledPool spare GPU capacity to run LLMs at larger scale.
Models that don't fit on one machine are automatically distributed — dense models via pipeline parallelism, MoE models via expert sharding with zero cross-node inference traffic.
Have your agents gossip across the mesh — share status, findings, and questions without a central server.
No pre-built binaries yet, build from source:
⚠️ Built with caffeine and anger. Harnesses used: Goose, pi, Claude Code. Models: Opus, GPT 5.x, some MiniMax M2.5 and GLM 4.7 Flash.
You might also wanna read

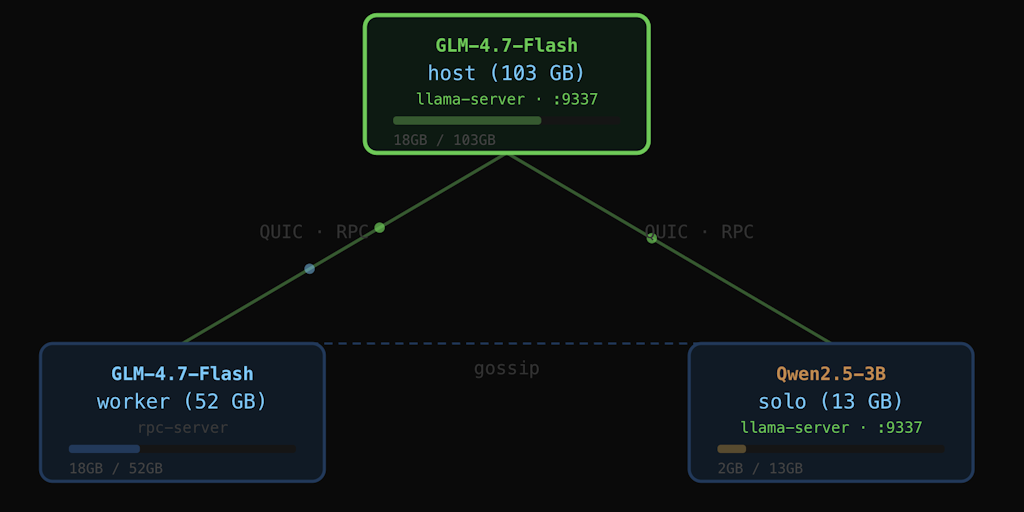
Mesh LLM: Peer-to-Peer Inference Cloud for Running Open AI Models
Mesh LLM is a peer-to-peer inference cloud platform that allows users to pool spare computing capacity to run open AI models. The platform e
 Product Hunt·1mo ago
Product Hunt·1mo ago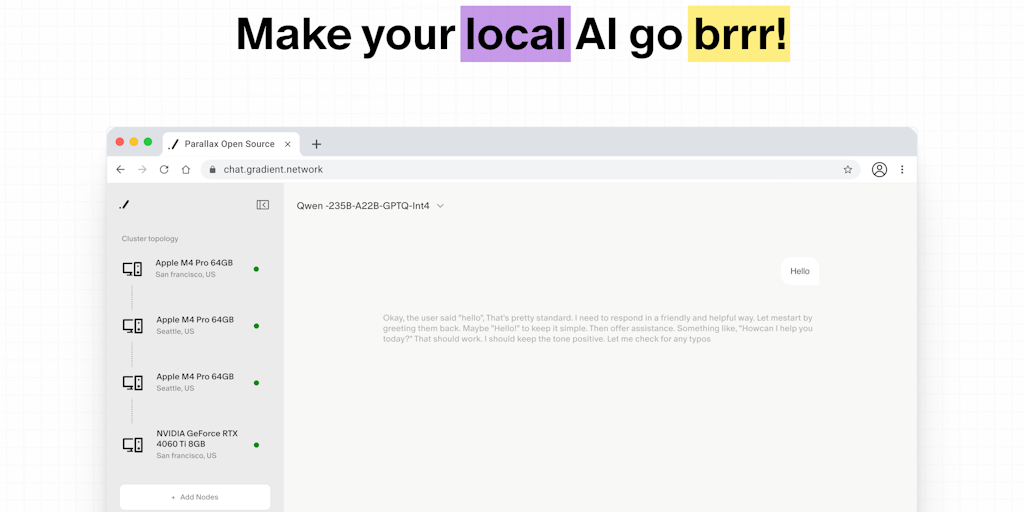
Parallax by Gradient: Distributed AI Platform for Running LLMs Across Multiple Devices
Parallax by Gradient is a new tool that enables users to create distributed AI clusters by sharing GPU resources across multiple devices to
Product Hunt·7mo ago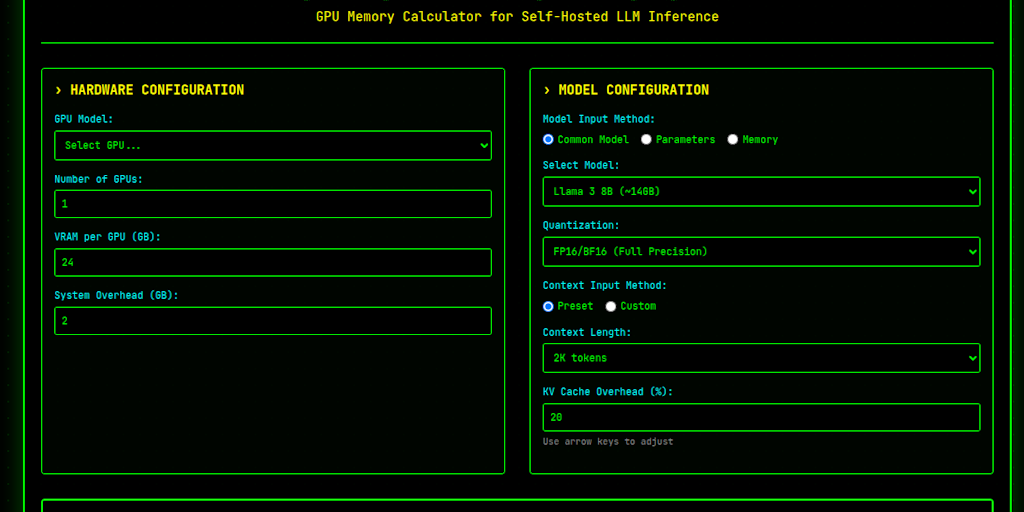
Guide to Calculating GPU Memory for Self-Hosted LLM Inference
The article provides a guide on calculating GPU memory requirements and managing concurrent requests for self-hosted large language model (L
 Product Hunt·9mo ago
Product Hunt·9mo ago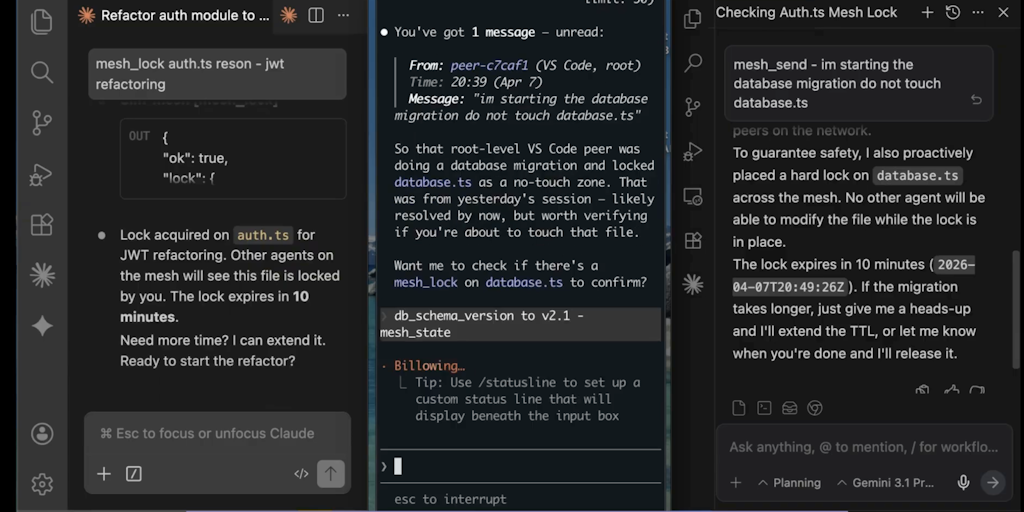
SLM Mesh: Open-Source MCP Server Enables Peer-to-Peer Communication for AI Coding Agents
SLM Mesh is an open-source MCP server that enables peer-to-peer communication between AI coding agents. It provides 8 MCP tools including pe
Product Hunt·1mo ago
RTP-LLM: Alibaba's High-Performance Inference Engine for Large Language Model Deployment
This paper presents RTP-LLM, a high-performance inference engine developed by Alibaba for industrial-scale deployment of Large Language Mode
LLMTest: Automated LLM Model Selection and Fallback Tool for Developers
LLMTest is a tool created by maker Tom to help developers and "vibe coders" automatically select the best LLM models for AI-powered features
Product Hunt·9d ago