LoomVideo: A 5B-Parameter Unified Model for Efficient Video Generation and Editing
By
[Submitted on 4 Jun 2026]
Pulled from the oven just right. Trustworthy, fact-dense, deeply satisfying.
Summary
LoomVideo is a new 5-billion parameter unified architecture for video generation and editing that addresses computational bottlenecks in existing models. It replaces standard text encoders with a Multimodal Large Language Model (MLLM) and introduces a zero-overhead Scale-and-Add conditioning approach for video editing, eliminating the need for token concatenation that typically quadruples computational complexity. The model achieves state-of-the-art performance across benchmarks, particularly excelling in e-commerce and fashion generation, while delivering at least 5.41x faster inference speed compared to similar-capability models.
Key quotes
· 4 pulledDeveloping unified video generation and editing models capable of interpreting interleaved multimodal inputs is a promising yet challenging frontier field.
We present LoomVideo, a highly efficient 5B-parameter unified architecture for both video generation and editing.
By scaling and directly adding the clean source video latent to the noised target latent, this elegant design eliminates the need for token concatenation, drastically reducing computational cost while maintaining robust capabilities for complex, non-rigid edits.
Benefiting from the zero-overhead conditioning mechanism, LoomVideo achieves at least a 5.41x acceleration in inference speed compared to models of similar capabilities, paving the way for highly practical and efficient video foundation models.
You might also wanna read


StreamingVLM: Real-Time Vision-Language Model for Infinite Video Stream Processing
StreamingVLM is a new vision-language model designed for real-time understanding of infinite video streams, addressing the computational cha

Helios: A 14B Parameter Real-Time Video Generation Model for Minute-Scale Content
Helios is a 14B parameter video generation model that achieves real-time performance at 19.5 FPS on a single NVIDIA H100 GPU while supportin
 alphaxiv.org·3mo ago
alphaxiv.org·3mo ago
Lumina-DiMOO: Open-Source Multimodal AI Model Using Discrete Diffusion for Cross-Modal Generation
Lumina-DiMOO is an open-source foundational model that uses discrete diffusion modeling for multimodal generation and understanding across v

ByteDance Releases Lance: A 3B-Parameter Unified Multimodal Model for Image and Video Tasks
ByteDance has released Lance, a 3B-active-parameter native unified multimodal model capable of handling image and video understanding, gener
 github.com·21d ago
github.com·21d ago
Capybara: A Unified Visual Creation Model for Visual Synthesis and Editing
Capybara is a unified visual creation model and framework for high-quality visual synthesis and manipulation tasks. It leverages advanced di
github.com·3mo ago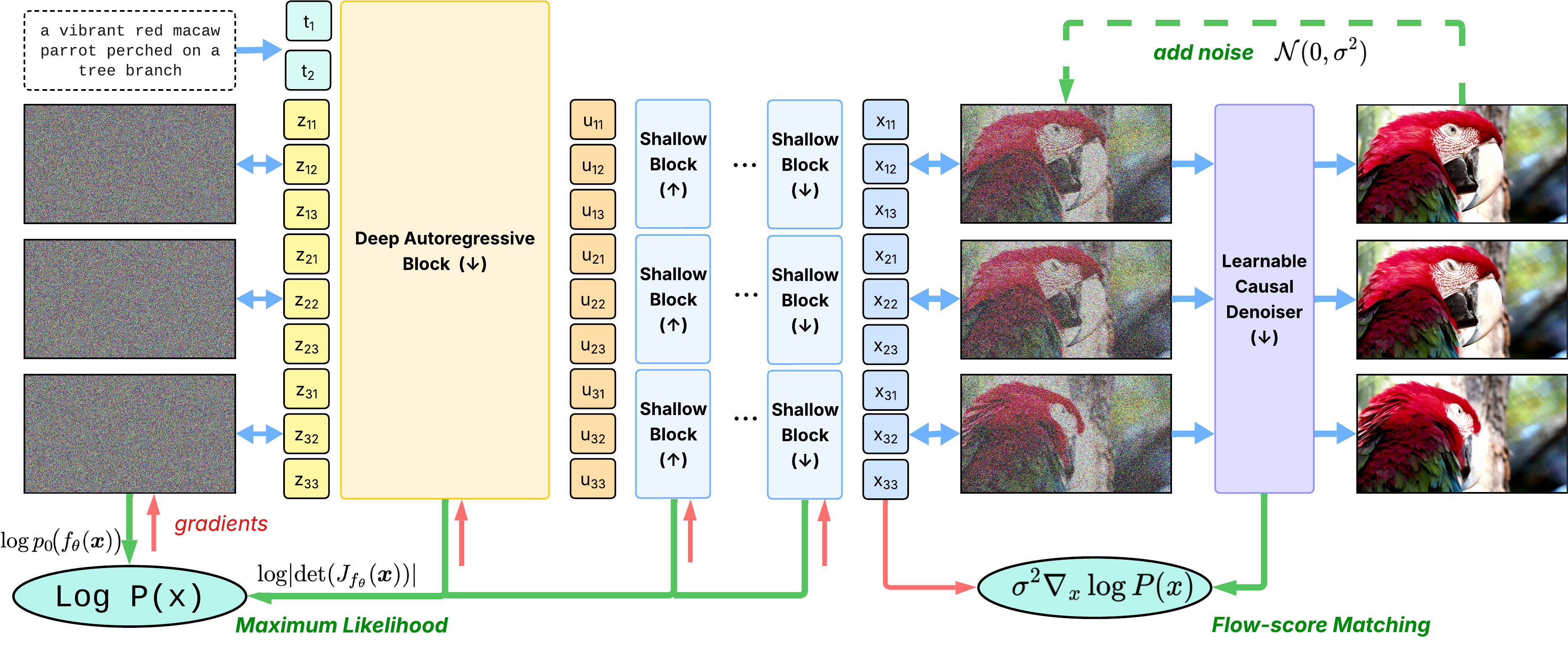
STARFlow-V: Normalizing Flow-Based Video Generation Model with End-to-End Learning
STARFlow-V is a normalizing flow-based video generation model that offers end-to-end learning, robust causal prediction, and native likeliho