LMSYS Announces Day-0 Open-Source Support for DeepSeek-V4 with SGLang and Miles Stack
By
mji
Hand-rolled, kettle-boiled, baked to perfection. Worth every minute at the bakery.
Summary
LMSYS Blog announces Day-0 support for DeepSeek-V4, a new AI model, with SGLang and Miles forming the first open-source stack for both inference and RL training. The systems are purpose-built for DeepSeek-V4's hybrid sparse-attention architecture, manifold-constrained hyper-connections (mHC), and FP4 expert weights. The article includes benchmark comparisons showing SGLang's decode throughput performance against other open-source engines on a long-context prompt.
Key quotes
· 2 pulledWe are thrilled to announce Day-0 support for DeepSeek-V4 across both inference and RL training.
SGLang and Miles form the first open-source stack to serve and train DeepSeek-V4 on launch day — with systems purpose-built for its hybrid sparse-attention architecture, manifold-constrained hyper-connections (mHC), and FP4 expert weights.
You might also wanna read


DeepSeek-V3.1: Open-Source Language Model with Hybrid Inference for Advanced Reasoning and Coding
DeepSeek-V3.1 is an open-source large language model that introduces hybrid inference with both 'Think' and 'Non-Think' modes, optimized for
 Product Hunt·9mo ago
Product Hunt·9mo ago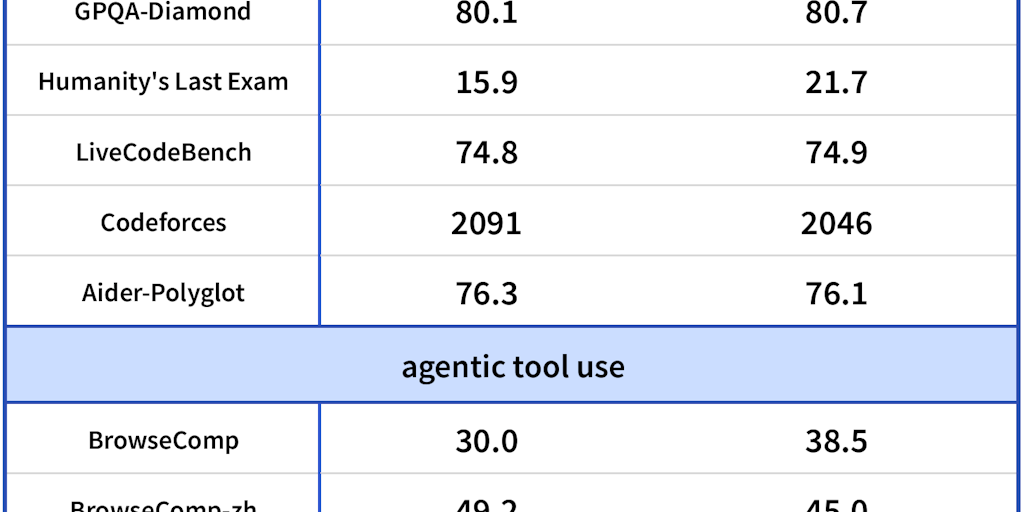
DeepSeek-V3.1-Terminus: Latest Open-Source LLM with Enhanced Stability and Agent Capabilities
DeepSeek-V3.1-Terminus is the latest open-source large language model from DeepSeek, representing the 7th launch in their series. This refin
 Product Hunt·1mo ago
Product Hunt·1mo ago
DeepSeek previews V4 AI model, claims competitiveness with US rivals and Huawei compatibility
Chinese AI company DeepSeek has released a preview of its next-generation AI model V4, claiming it can compete with leading closed-source sy

DeepSeek's V4 Model Shows Widening Gap with US Frontier AI Despite Being China's Best
DeepSeek's latest V4 model release was met with a muted reaction, as analysis by the US National Institute for Standards and Technology foun
 bloomberg.com·4d ago
bloomberg.com·4d ago
DeepSeek-V4: Hybrid Sparse-Attention Architecture Enables Efficient Million-Token Context Inference
DeepSeek-V4 introduces a hybrid sparse-attention architecture combined with on-policy distillation across domain specialists, enabling 1M-to
 artgor.medium.com·16h ago
artgor.medium.com·16h ago
RTP-LLM: Alibaba's High-Performance Inference Engine for Large Language Model Deployment
This paper presents RTP-LLM, a high-performance inference engine developed by Alibaba for industrial-scale deployment of Large Language Mode