Introduction of Qwen VLo: A Unified Multimodal Understanding and Generation Model
By
lnyan
Slow-proofed and worth the wait. Worth its weight in flour.
Summary
The article introduces the Qwen VLo model, a unified multimodal understanding and generation model that bridges the gap between perception and creation by not only understanding the world but also generating high-quality recreations based on that understanding.
Key quotes
· 3 pulledFrom the initial QwenVL to the latest Qwen2.5 VL, we have made progress in enhancing the model’s ability to understand image content.
Today, we are excited to introduce a new model, Qwen VLo, a unified multimodal understanding and generation model.
This newly upgraded model not only “understands” the world but also generates high-quality recreations based on that understanding, truly bridging the gap between perception and creation.
You might also wanna read

Qwen-VL: Multimodal AI Model for Visual Understanding and Reasoning
Qwen-VL is a powerful multimodal AI model from the Qwen team that excels in visual understanding capabilities including image question answe
 Product Hunt·9mo ago
Product Hunt·9mo ago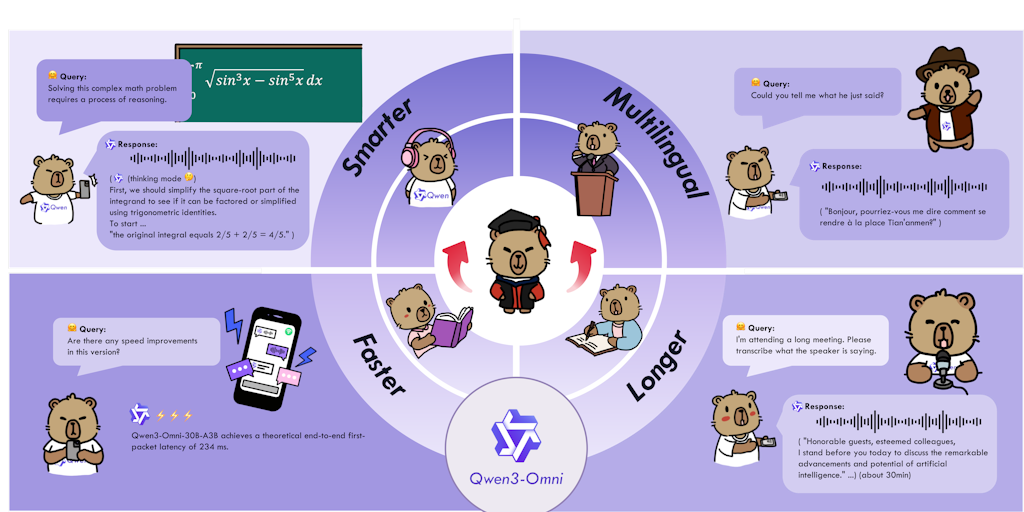
Alibaba Cloud Launches Qwen3-Omni: Native Multimodal AI Model with Real-Time Speech Generation
Qwen3-Omni is a new multimodal large language model from Alibaba Cloud's Qwen team that can process text, audio, images, and video natively
Product Hunt·1mo ago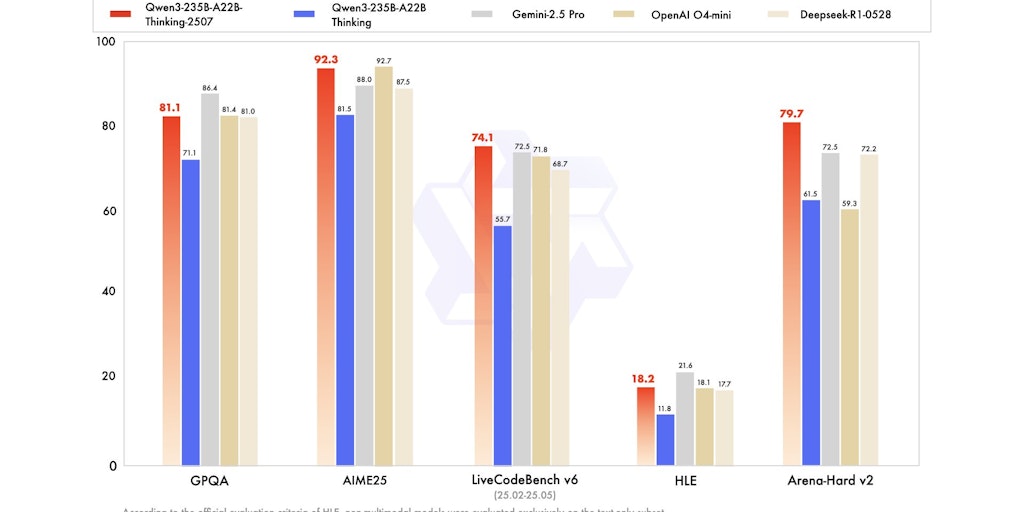
Qwen3: Alibaba Cloud's Large Language Model Series
The article introduces Qwen3, a large language model series developed by the Qwen team at Alibaba Cloud. It highlights the model's capabilit
 Product Hunt·10mo ago
Product Hunt·10mo agoQwen3: Alibaba Cloud's Large Language Model Series
The article introduces Qwen3, a large language model series developed by the Qwen team at Alibaba Cloud. It highlights the model's capabilit
Product Hunt·10mo ago
Qwen Announces QWQ-Max-Preview LLM with Enhanced Reasoning and Thinking Mode
Qwen has released QWQ-Max-Preview, a new large language model that excels in reasoning, mathematics, coding, and agent tasks. The model feat
Product Hunt·10mo ago