Implementing a Markov Text Generator with 24 Years of Blog Posts
By
zdw
A baker's-dozen of insight crammed into one ring.
Summary
The article describes the author's implementation of a Markov text generator called Mark V. Shaney Junior, inspired by the original 1980s program that generated synthetic Usenet posts. The author explains how they fed 24 years of their blog posts into this Markov model to generate new text, discusses the technical implementation details, and shares examples of the output produced by the model.
Key quotes
· 3 pulledIt is a minimal implementation of a Markov text generator inspired by the legendary Mark V. Shaney program from the 1980s.
Mark V. Shaney was a synthetic Usenet user that posted messages to various newsgroups using text generated by a Markov model.
In this post, I will discuss my implementation of the model, explain how it works and share some of the results produced by it.
You might also wanna read


NVIDIA Announces "Hack for Impact" London Event for Autonomous AI Agent Development
NVIDIA is hosting a "Hack for Impact" event in London, challenging participants to build autonomous agentic applications using open-source m
 luma.com·6h ago
luma.com·6h ago
MerLean-Prover: A Recursive Agent Harness for Lean 4 Theorem Proving Outperforms Baselines
MerLean-Prover is an end-to-end Lean4 theorem prover that replaces 'sorry' declarations with kernel-checkable proofs using three agent types

Reflections on DwarfStar 4's rapid rise in local AI inference
The author reflects on the unexpected popularity of DwarfStar 4 (DS4), a local AI inference project. They attribute its success to the conve
antirez.com·1d agoReflections on DwarfStar 4's rapid rise in local AI inference
The author reflects on the unexpected popularity of DwarfStar 4 (DS4), a local AI inference project. They attribute its success to the conve
antirez.com·1d ago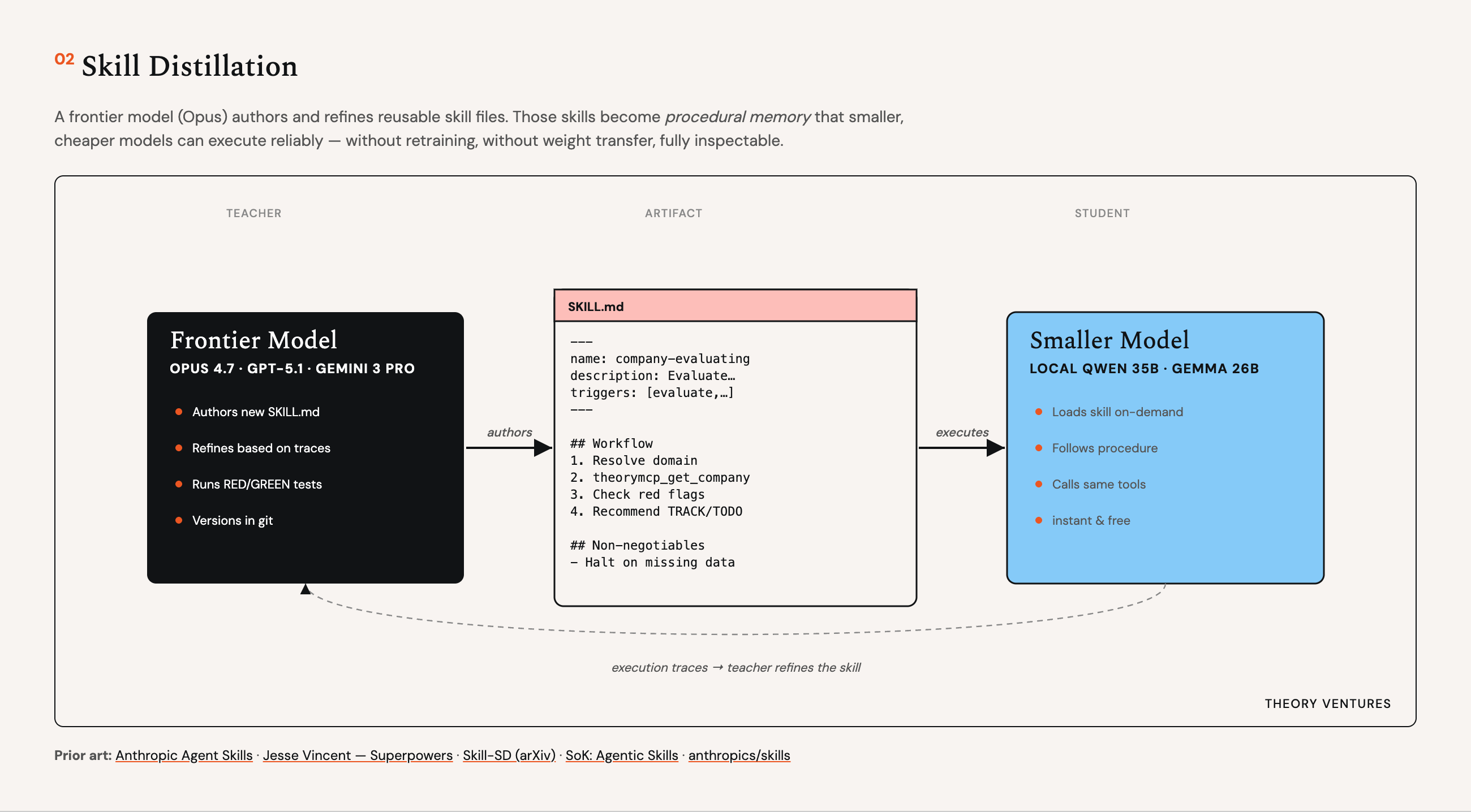
Building a Personal AI Agent with Markdown-Based Skills and Local Models
The article describes a personal AI agent built on Pi that manages the author's inbox, calendar, deal pipeline, blog publishing, and researc
 tomtunguz.com·2d ago
tomtunguz.com·2d ago
StepFun Releases Step 3.5 Flash: 196B Sparse MoE Model for OpenClaw Agents
StepFun has released Step 3.5 Flash, a 196B sparse Mixture of Experts (MoE) model that activates only 11B parameters per token for high effi
 Product Hunt·2d ago
Product Hunt·2d ago