Four practical steps to control Azure Foundry token costs for agentic AI workloads
By
Lewis Prince
Crackling crust, pillowy middle. The kind of bagel that earns a second cup of coffee.
Summary
This article provides practical guidance on controlling token costs in Microsoft Azure Foundry, particularly for agentic AI workloads where a single user action can trigger multiple LLM calls. It outlines four low-effort strategies to prevent runaway spending: setting TPM (tokens per minute) limits on deployments, implementing budget alerts, using token-based rate limiting, and monitoring usage dashboards. The piece emphasizes proactive cost management before unexpected bills arrive.
Key quotes
· 3 pulledToken costs in production can surprise you fast.
Without visibility, you won't know there's a problem until the bill arrives. By then, the damage is done.
Set them per deployment so a rogue agent run can't burn through your budget before anyone notices.
You might also wanna read


Microsoft Abandons Anthropic's Claude Code Over Uncontrolled Token-Based Billing Costs
Microsoft dropped its internal use of Anthropic's Claude Code after experiencing unsustainable budget overruns due to token-based billing fo
 aiweekly.co·9d ago
aiweekly.co·9d ago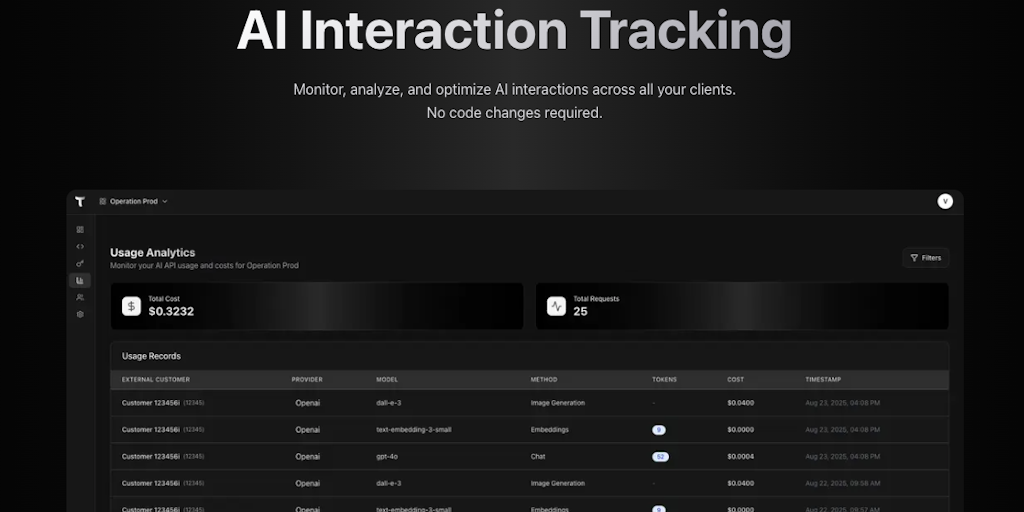
Tokyo AI: Developer Tool for Tracking and Managing AI Usage Costs Across Clients
Tokyo AI is a developer tool created to solve the problem of tracking and managing AI usage costs across multiple clients. The founder devel
 Product Hunt·9mo ago
Product Hunt·9mo ago