Google releases Gemma 4 QAT checkpoints for efficient on-device AI model deployment
By
Olivier Lacombe
Crusty in the right places. Worth the chew.
Summary
Google is releasing new Gemma 4 checkpoints optimized with Quantization-Aware Training (QAT) to improve model compression and efficiency. These checkpoints reduce memory requirements and enable running large language models locally on edge devices like mobile phones and laptops, as well as consumer GPUs. This follows previous Gemma 4 updates including Multi-Token Prediction (MTP) and a 12B model release.
Key quotes
· 3 pulledToday, we are releasing new checkpoints optimized with Quantization-Aware Training (QAT) to make Gemma 4 even more efficient, so you can run models locally on everyday edge devices and consumer GPUs.
By simulating quantization during training...
Since releasing Gemma 4 two months ago, we've been continuously working to expand its capabilities.
You might also wanna read

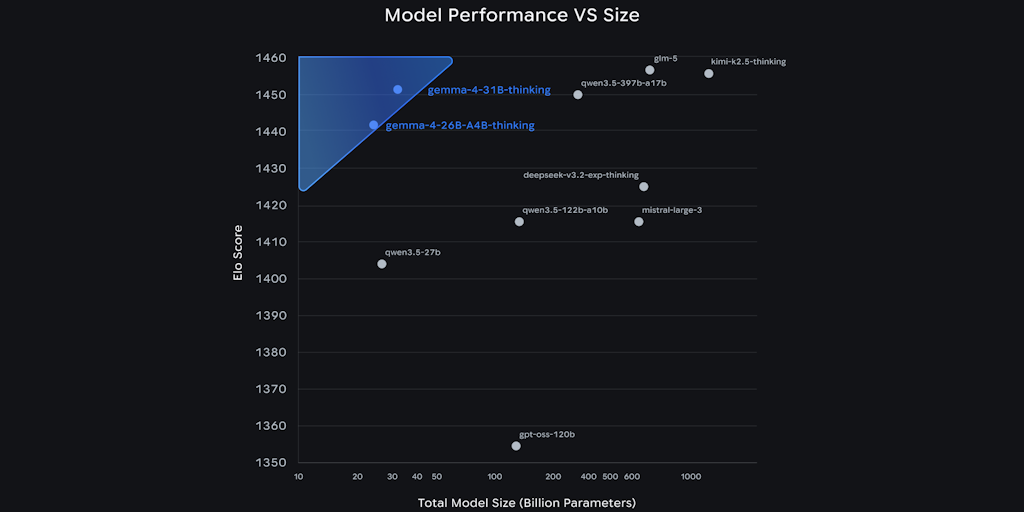
Google DeepMind Releases Gemma 4: Most Advanced Open AI Model Family
Google DeepMind has released Gemma 4, its most advanced open AI model family to date. The models feature enhanced reasoning capabilities, mu
 Product Hunt·2mo ago
Product Hunt·2mo ago
Google DeepMind's Gemma 4 12B: Encoder-free multimodal AI runs locally on 16GB VRAM
Google DeepMind's Gemma 4 12B is an open-source multimodal AI model that processes text, images, and audio natively on consumer hardware wit
Product Hunt·2d ago
TranslateGemma: Open AI Translation Models Based on Google's Gemma 3 Support 55 Languages
TranslateGemma is a new suite of open AI translation models built on Google's Gemma 3 framework, supporting 55 languages with high accuracy
Product Hunt·4mo ago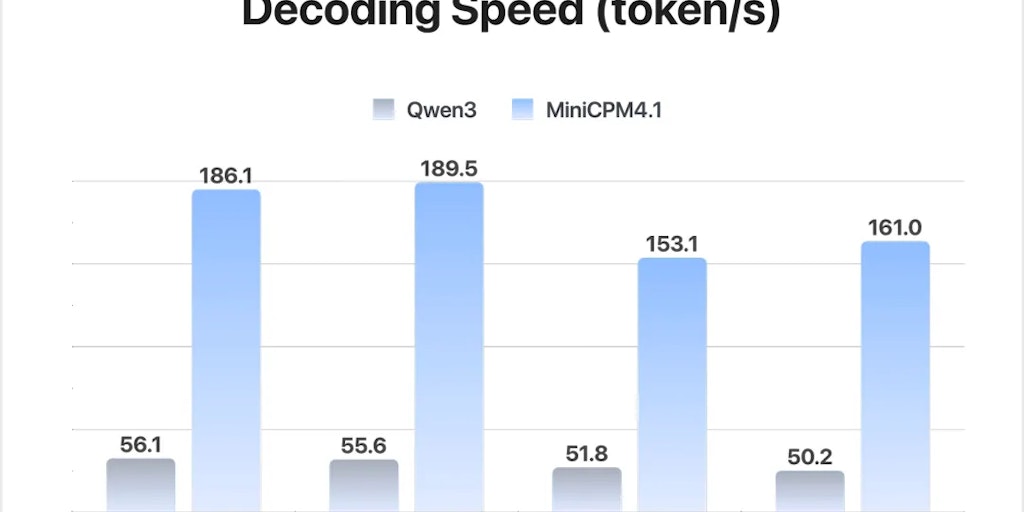
MiniCPM 4.0: Ultra-Efficient Open-Source AI Models for On-Device Deployment
MiniCPM 4.0 is an ultra-efficient, open-source AI model family designed for on-device deployment, featuring significant speed improvements o
Product Hunt·8mo ago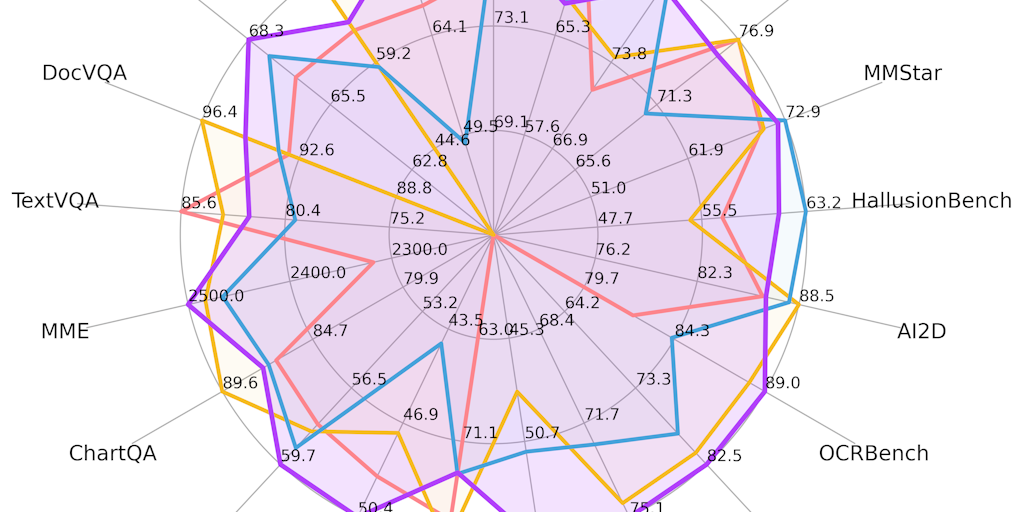
MiniCPM 4.0: Open-source 8B multimodal AI model outperforms GPT-4o and Gemini Pro on vision benchmarks
MiniCPM 4.0 is an ultra-efficient 8B open-source multimodal AI model designed for on-device use that outperforms larger models like GPT-4o a
 Product Hunt·9mo ago
Product Hunt·9mo ago
MiniCPM 4.0: Ultra-Efficient Open-Source AI Models for On-Device Deployment
MiniCPM 4.0 is a family of ultra-efficient, open-source AI models designed for on-device deployment, offering significant speed improvements
Product Hunt·1y ago