Google launches Gemma 4 12B: an encoder-free multimodal AI model for laptops
By
Olivier Lacombe
Master baker tier. Every paragraph earns its place on the tray.
Summary
Google has introduced Gemma 4 12B, a unified, encoder-free multimodal AI model designed to run high-performance intelligence directly on laptops. The model processes text, images, and video natively without needing a separate encoder, making it efficient for local deployment. It is available for experimentation via tools like LM Studio, Ollama, and Google AI Edge platforms, with pre-downloadable weights for developers.
Key quotes
· 3 pulledGet started today
Try it yourself: Experiment with a couple of clicks in LM Studio, Ollama, Google AI Edge Gallery App, the Google AI Edge Eloquent app and the LiteRT-LM CLI
Download the weights: Download the pre-
You might also wanna read

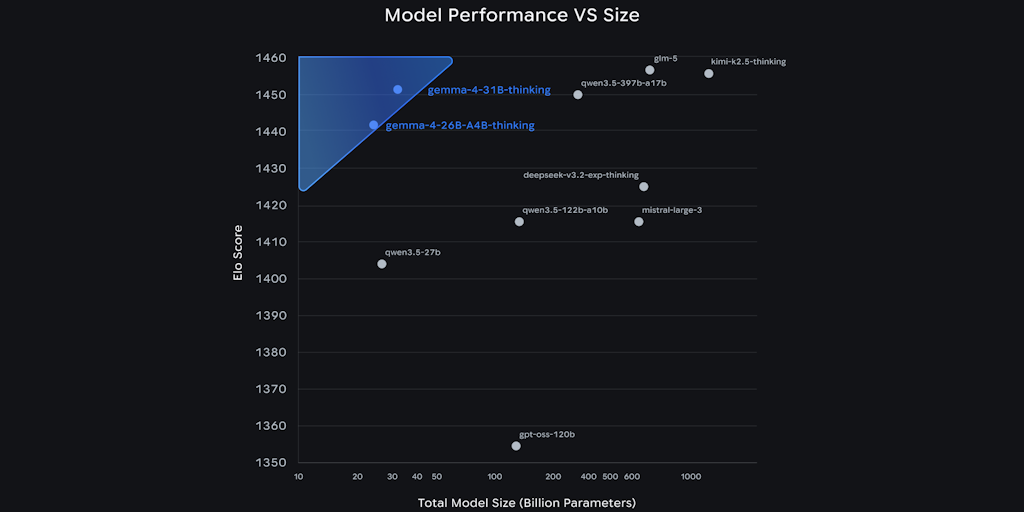
Google DeepMind Releases Gemma 4: Most Advanced Open AI Model Family
Google DeepMind has released Gemma 4, its most advanced open AI model family to date. The models feature enhanced reasoning capabilities, mu
 Product Hunt·2mo ago
Product Hunt·2mo ago
TranslateGemma: Open AI Translation Models Based on Google's Gemma 3 Support 55 Languages
TranslateGemma is a new suite of open AI translation models built on Google's Gemma 3 framework, supporting 55 languages with high accuracy
Product Hunt·4mo ago
TwelveLabs AI Platform for Deep Video Understanding and Analysis
TwelveLabs is an AI platform that provides deep video understanding capabilities using multimodal models (Marengo/Pegasus). The platform ena
Product Hunt·20d ago
MiniCPM 4.0: Open-source 8B multimodal AI model outperforms GPT-4o and Gemini Pro on vision benchmarks
MiniCPM 4.0 is an ultra-efficient 8B open-source multimodal AI model designed for on-device use that outperforms larger models like GPT-4o a
 Product Hunt·9mo ago
Product Hunt·9mo ago
Google Releases 'Nano-Banana' Multimodal AI Model with Advanced Image and Language Capabilities
Google has released a new multimodal AI model called 'nano-banana' that demonstrates exceptional character consistency and advanced capabili
Product Hunt·9mo ago
Ollama v0.7 Launches New Engine for Local Vision Model Execution
Ollama v0.7 introduces a new engine designed for running leading vision models locally, such as Llama 4 and Gemma 3. The update focuses on i
Product Hunt·10mo ago