Gemma 3n: Advanced On-Device Multimodal Capabilities for Edge Devices
By
bundie
An everything bagel for the brain. Substantive, layered, well-seasoned.
Summary
The Gemma 3n model has been fully released, offering advanced on-device multimodal capabilities to edge devices with unprecedented performance. It builds on the success of previous Gemma models and introduces innovations like mobile-first architecture, MatFormer technology, Per-Layer Embeddings, KV Cache Sharing, and new audio and MobileNet-V5 vision encoders.
Key quotes
· 3 pulledThe first Gemma model launched early last year and has since grown into a thriving Gemmaverse of over 160 million collective downloads.
From innovators like Roboflow building enterprise computer vision to the Institute of Science Tokyo creating highly-capable Japanese Gemma variants, your work has shown us the path forward.
Building on th
You might also wanna read

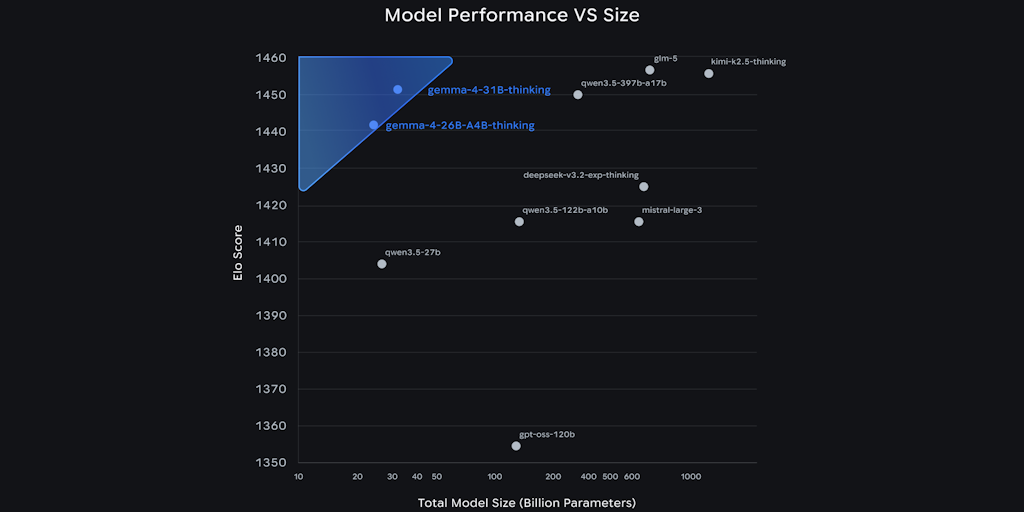
Google DeepMind Releases Gemma 4: Most Advanced Open AI Model Family
Google DeepMind has released Gemma 4, its most advanced open AI model family to date. The models feature enhanced reasoning capabilities, mu
 Product Hunt·1mo ago
Product Hunt·1mo ago
TranslateGemma: Open AI Translation Models Based on Google's Gemma 3 Support 55 Languages
TranslateGemma is a new suite of open AI translation models built on Google's Gemma 3 framework, supporting 55 languages with high accuracy
Product Hunt·4mo ago
Google Unveils Gemini: A Multimodal AI Model to Rival GPT-4
Google's Gemini is introduced as its largest and most capable AI model, designed to be multimodal and capable of understanding and combining
 Product Hunt·9mo ago
Product Hunt·9mo ago
Google Releases Gemini Embedding 2: First Natively Multimodal Embedding Model
Google has released Gemini Embedding 2, its first natively multimodal embedding model that can map text, images, video, audio, and documents
Product Hunt·2mo ago
MiniCPM 4.0: Open-source 8B multimodal AI model outperforms GPT-4o and Gemini Pro on vision benchmarks
MiniCPM 4.0 is an ultra-efficient 8B open-source multimodal AI model designed for on-device use that outperforms larger models like GPT-4o a
Product Hunt·9mo ago