FrontierCode: A New Benchmark for Measuring AI Code Quality Beyond Correctness
By
streamer45
The kind of bagel that ruins lesser bagels for you.
Summary
FrontierCode is a new benchmark introduced by a team of researchers and engineers that aims to measure not just whether AI models can write correct code, but whether they can write high-quality, production-ready code. The article argues that as AI-generated code becomes more prevalent in production environments, correctness alone is no longer sufficient—code quality, maintainability, and adherence to production standards are now the critical metrics. The benchmark is designed to evaluate models against the standards of high-quality production codebases.
Key quotes
· 3 pulledToday's coding benchmarks have established that models can write correct code. But as AI-generated code becomes the dominant path to production, correctness is now table stakes.
The question that we should be asking is: can models actually write good code?
We're excited to introduce FrontierCode, a benchmark that measures how well models can truly meet the standards of high-quality production codebases.
You might also wanna read


Epoch AI criticized for delayed disclosure of OpenAI funding for FrontierMath benchmark
Epoch AI, a nonprofit organization that developed FrontierMath (a benchmark for measuring AI mathematical skills), is facing criticism for n
 techcrunch.com·5d ago
techcrunch.com·5d ago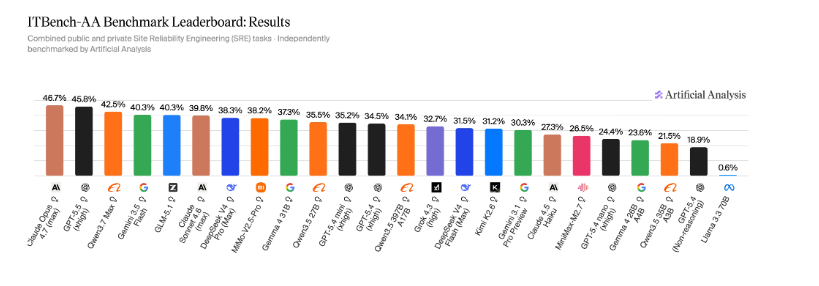
ITBench-AA Benchmark Launched: Frontier AI Models Score Below 50% on Enterprise IT Tasks
Artificial Analysis and IBM Software Innovation Lab have launched ITBench-AA, a new benchmark series evaluating AI models on agentic enterpr

AutonomyAI Launches Fei: An AI-Powered Autonomous Engineer for Production-Ready Code
AutonomyAI introduces Fei, an AI-powered autonomous engineer designed to streamline software development by converting requirements into pro
 Product Hunt·10mo ago
Product Hunt·10mo ago