CUDA-L2: AI-Optimized Matrix Multiplication Outperforms NVIDIA cuBLAS
By
dzign
Hand-rolled, kettle-boiled, baked to perfection. Worth every minute at the bakery.
Summary
CUDA-L2 is a system that uses large language models and reinforcement learning to automatically optimize half-precision matrix multiplication CUDA kernels. The system systematically outperforms major matrix multiplication baselines including torch.matmul and NVIDIA's closed-source libraries (cuBLAS, cuBLASLt-heuristic, cuBLASLt-AutoTuning) across various GPU configurations including RTX 3090, A100, and H100. The research demonstrates significant speedups over existing solutions through AI-driven optimization of HGEMM kernels.
Key quotes
· 3 pulledCUDA-L2 is a system that combines large language models (LLMs) and reinforcement learning (RL) to automatically optimize Half-precision General Matrix Multiply (HGEMM) CUDA kernels.
CUDA-L2 systematically outperforms major matmul baselines to date, from the widely-used torch.matmul to state-of-the-art NVIDIA closed-source libraries (cuBLAS, cuBLASLt-heuristic, cuBLASLt-AutoTuning).
Summary of CUDA-L2 speedup over baselines across all GPU configurations (RTX 3090-F32F16F16F32, A100-F16F16F16F16, A100-F32F16F16F32, H100-F32F16F16F32) in Offline and S
You might also wanna read


Technical Implementation of DeepSeek LLM Deployment with Expert Parallelism on 96 H100 GPUs
The article details the technical implementation of deploying DeepSeek, an open-source large language model, across 96 H100 GPUs using advan
 lmsys.org·9mo ago
lmsys.org·9mo ago
Reflections on DwarfStar 4's rapid rise in local AI inference
The author reflects on the unexpected popularity of DwarfStar 4 (DS4), a local AI inference project. They attribute its success to the conve
antirez.com·1d agoReflections on DwarfStar 4's rapid rise in local AI inference
The author reflects on the unexpected popularity of DwarfStar 4 (DS4), a local AI inference project. They attribute its success to the conve
antirez.com·1d ago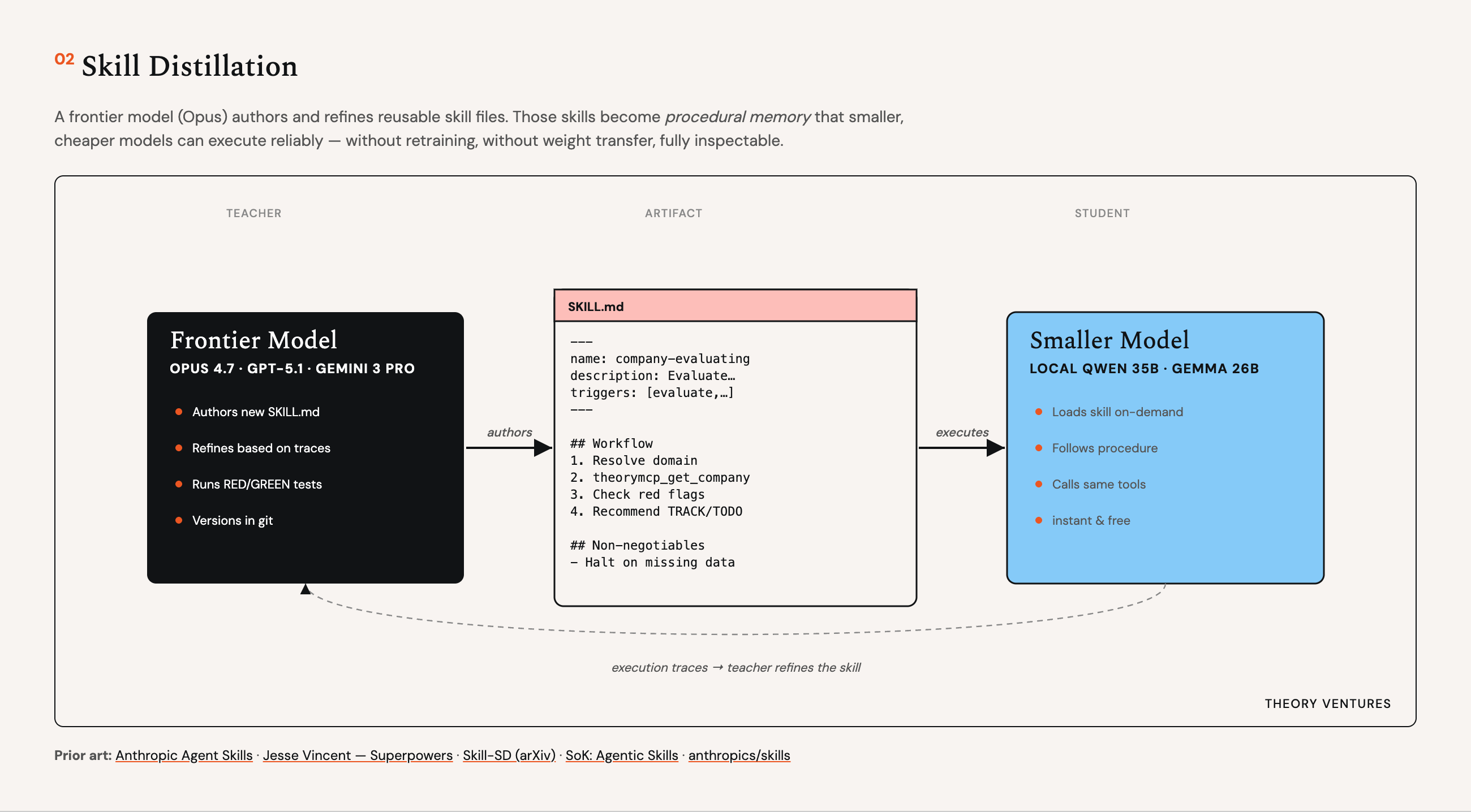
Building a Personal AI Agent with Markdown-Based Skills and Local Models
The article describes a personal AI agent built on Pi that manages the author's inbox, calendar, deal pipeline, blog publishing, and researc
 tomtunguz.com·2d ago
tomtunguz.com·2d ago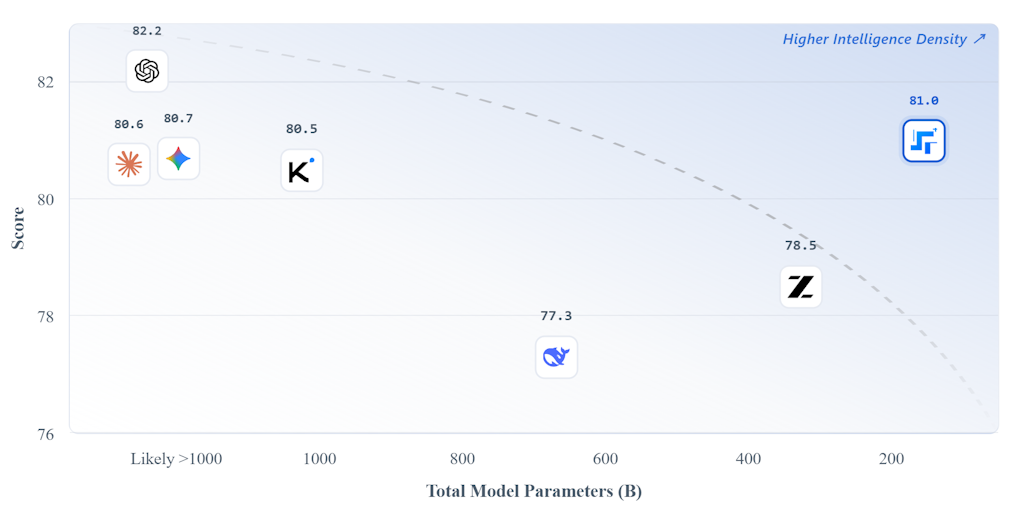
StepFun Releases Step 3.5 Flash: 196B Sparse MoE Model for OpenClaw Agents
StepFun has released Step 3.5 Flash, a 196B sparse Mixture of Experts (MoE) model that activates only 11B parameters per token for high effi
 Product Hunt·2d ago
Product Hunt·2d ago
Anthropic Releases Claude Opus 4.7 AI Model with 1M Context Window and Enhanced Coding Capabilities
Anthropic announces Claude Opus 4.7, their latest AI model featuring a hybrid reasoning architecture with a 1 million token context window.
 anthropic.com·2d ago
anthropic.com·2d ago