Building high-performance expert-parallel dispatch and combine kernels for MoE LLM inference
By
kkm
The bagel they save for the regulars. Don't skim, savour.
Summary
This article provides a deep technical deep-dive into the architecture and implementation of high-performance Expert Parallelism (EP) kernels for Mixture-of-Experts (MoE) large language models. It explains the challenges of GPU communication in distributed LLM inference, focusing on the dispatch and combine kernels used in expert-parallel systems. The article builds up both high-throughput and low-latency kernel designs from scratch, covering GPU memory management, communication patterns, and optimization techniques for scaling MoE model inference across multiple GPUs.
Key quotes
· 3 pulledLarge language models are large. Because they're large, we need lots of GPUs to run them.
To use lots of GPUs on LLM inference, we need to get those GPUs talking to one another.
All have their place. But for MoE models, in the MoE layers, when you want to serve at large scale, 'wide Expert'
You might also wanna read


RTP-LLM: Alibaba's High-Performance Inference Engine for Large Language Model Deployment
This paper presents RTP-LLM, a high-performance inference engine developed by Alibaba for industrial-scale deployment of Large Language Mode
Guide to Calculating GPU Memory for Self-Hosted LLM Inference
The article provides a guide on calculating GPU memory requirements and managing concurrent requests for self-hosted large language model (L
 Product Hunt·10mo ago
Product Hunt·10mo ago
APEX4: Platform-Dependent W4A4 LLM Inference via Intra-SM Compute Rebalancing
This paper presents APEX4, a system for efficient W4A4 (4-bit weights, 4-bit activations) LLM inference that addresses the bottleneck of gro
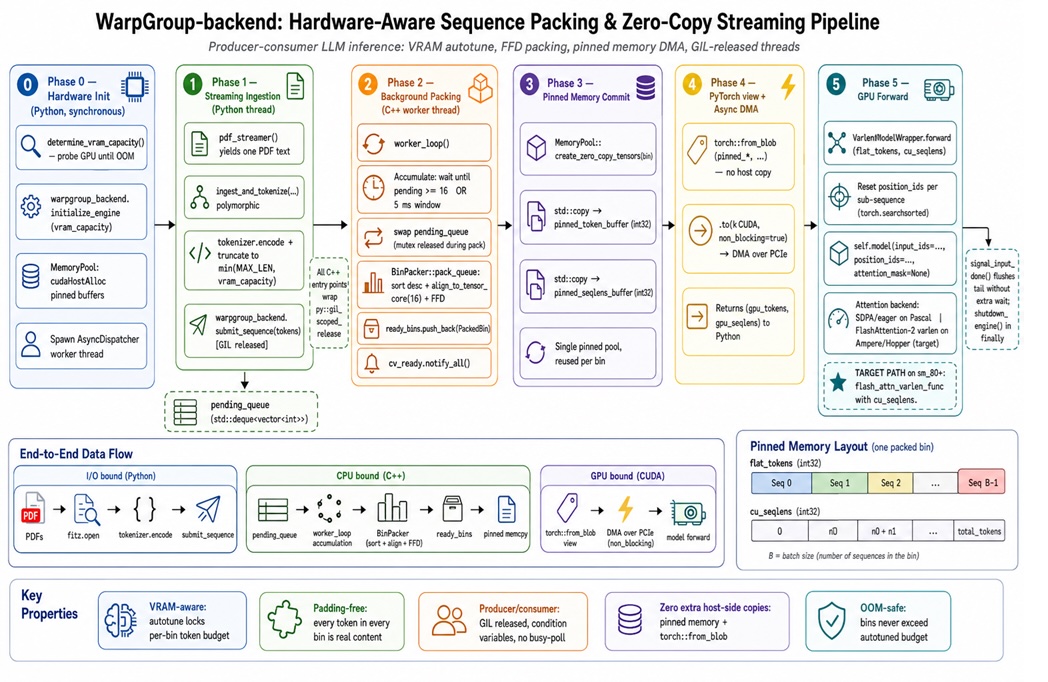
Optimizing LLM Inference: A C++ Backend for VRAM-Aware Sequence Packing
A technical deep-dive into optimizing LLM inference performance by eliminating wasteful padding in sequence batching. The article introduces
 towardsdatascience.com·8d ago
towardsdatascience.com·8d ago
LK Losses: A New Training Objective to Optimize Acceptance Rate in Speculative Decoding for LLMs
This paper introduces LK losses, a novel training objective for speculative decoding in large language models (LLMs). Speculative decoding a
General Compute Launches ASIC-Based Inference Cloud for Faster AI Agent Performance
General Compute is an inference cloud built on ASICs (purpose-built alternatives to Nvidia GPUs) designed specifically for AI inference, not
 Product Hunt·1mo ago
Product Hunt·1mo ago