Alibaba Releases Qwen3.5 Medium AI Models with Open Source Licensing and Near Sonnet 4.5 Performance
By
lostmsu
Hand-rolled, kettle-boiled, baked to perfection. Worth every minute at the bakery.
Summary
Alibaba's Qwen AI team has released the Qwen3.5 Medium Model series, consisting of four new large language models with agentic tool calling capabilities. Three models are available under the open source Apache 2.0 license for commercial use, while the fourth (Qwen3.5-Flash) is proprietary and available through Alibaba Cloud Model Studio API. The models offer near-lossless accuracy with 4-bit weight and KV cache quantization, enabling developers to process large datasets without requiring server-grade infrastructure. The performance is described as approaching that of Anthropic's Sonnet 4.5 model on local computers.
Key quotes
· 4 pulledAlibaba's now famed Qwen AI development team has done it again: a little more than a day ago, they released the Qwen3.5 Medium Model series consisting of four new large language models (LLMs) with support for agentic tool calling
three of which are available for commercial usage by enterprises and indie developers under the standard open source Apache 2.0 license
A fourth model, Qwen3.5-Flash, appears to be proprietary and only available through the Alibaba Cloud Model Studio API, but still offers a strong advantage in cost comp
This leap is made possible by near-lossless accuracy under 4-bit weight and KV cache quantization, allowing developers to process massive datasets without server-grade infrastructure
You might also wanna read

Qwen3: Alibaba Cloud's Large Language Model Series
The article introduces Qwen3, a large language model series developed by the Qwen team at Alibaba Cloud. It highlights the model's capabilit
Product Hunt·10mo ago

Qwen3: Alibaba Cloud's Open-Source Large Language Model Series for Coding Agents
Qwen3 is a large language model (LLM) series developed by the Qwen team at Alibaba Cloud, hosted on Product Hunt. The page showcases multipl
 Product Hunt·10mo ago
Product Hunt·10mo ago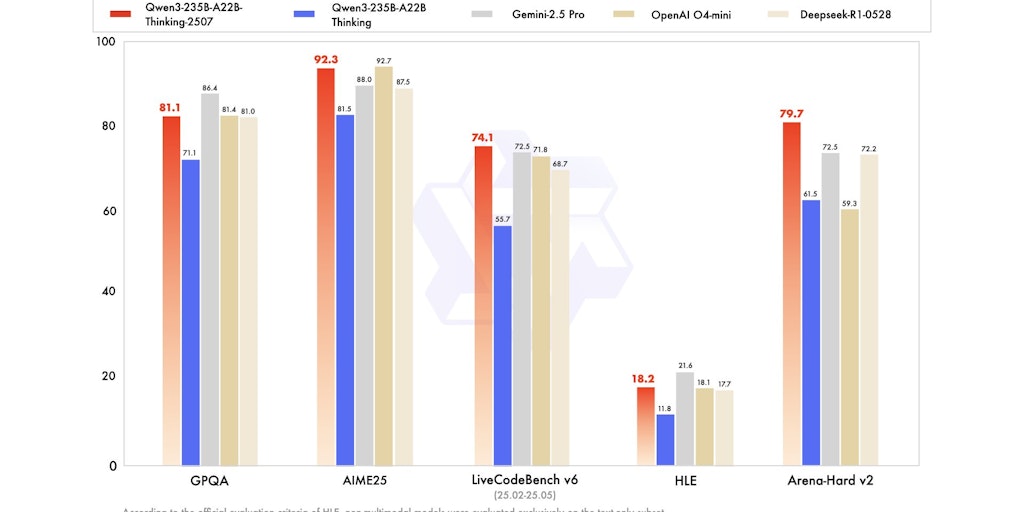
Qwen3: Alibaba Cloud's Large Language Model Series
The article introduces Qwen3, a large language model series developed by the Qwen team at Alibaba Cloud. It highlights the model's capabilit
Product Hunt·10mo ago
Alibaba Cloud Launches Qwen3-Omni: Native Multimodal AI Model with Real-Time Speech Generation
Qwen3-Omni is a new multimodal large language model from Alibaba Cloud's Qwen team that can process text, audio, images, and video natively
Product Hunt·1mo ago
Alibaba's Qwen3.7-Max ranks 4th globally in coding benchmark, beating OpenAI and Google models
Alibaba's latest AI model, Qwen3.7-Max, has secured the fourth spot globally on the Code Arena coding leaderboard with a score of 1,541, out
 scmp.com·4d ago
scmp.com·4d ago
Alibaba Tongyi Lab Launches Wan Series AI Models for Video and Image Generation
Alibaba's Tongyi Lab has launched the Wan series, a family of advanced foundational models for high-fidelity video and image generation. The
Product Hunt·5mo ago